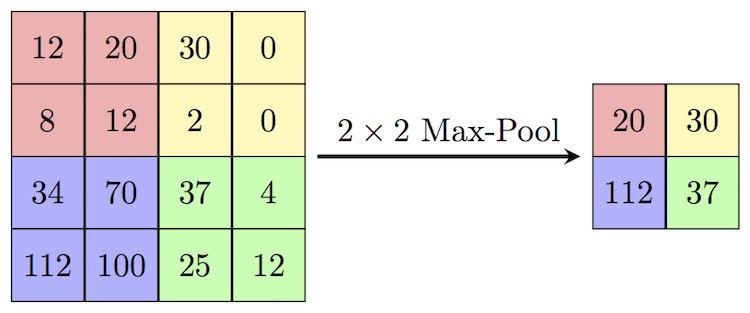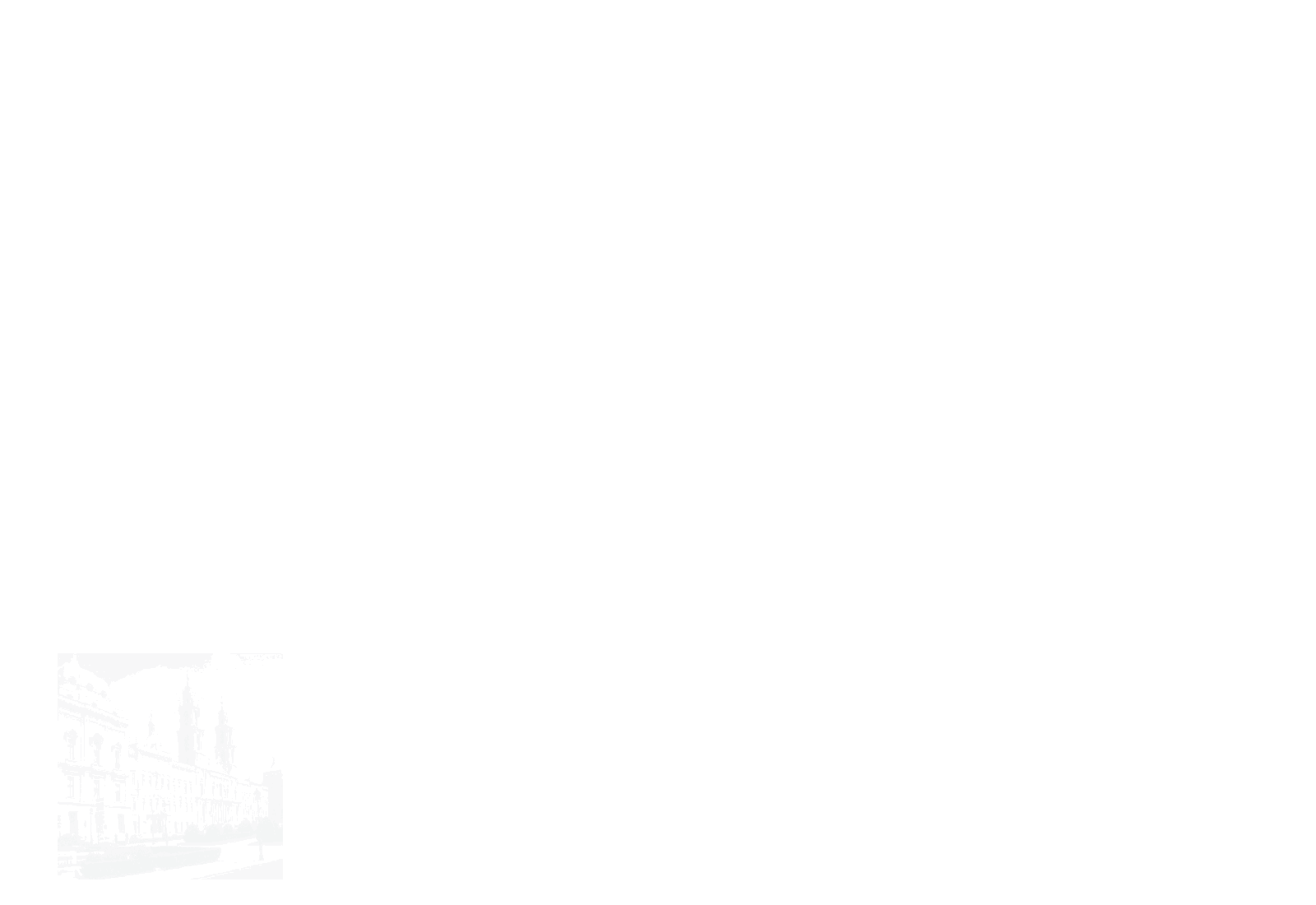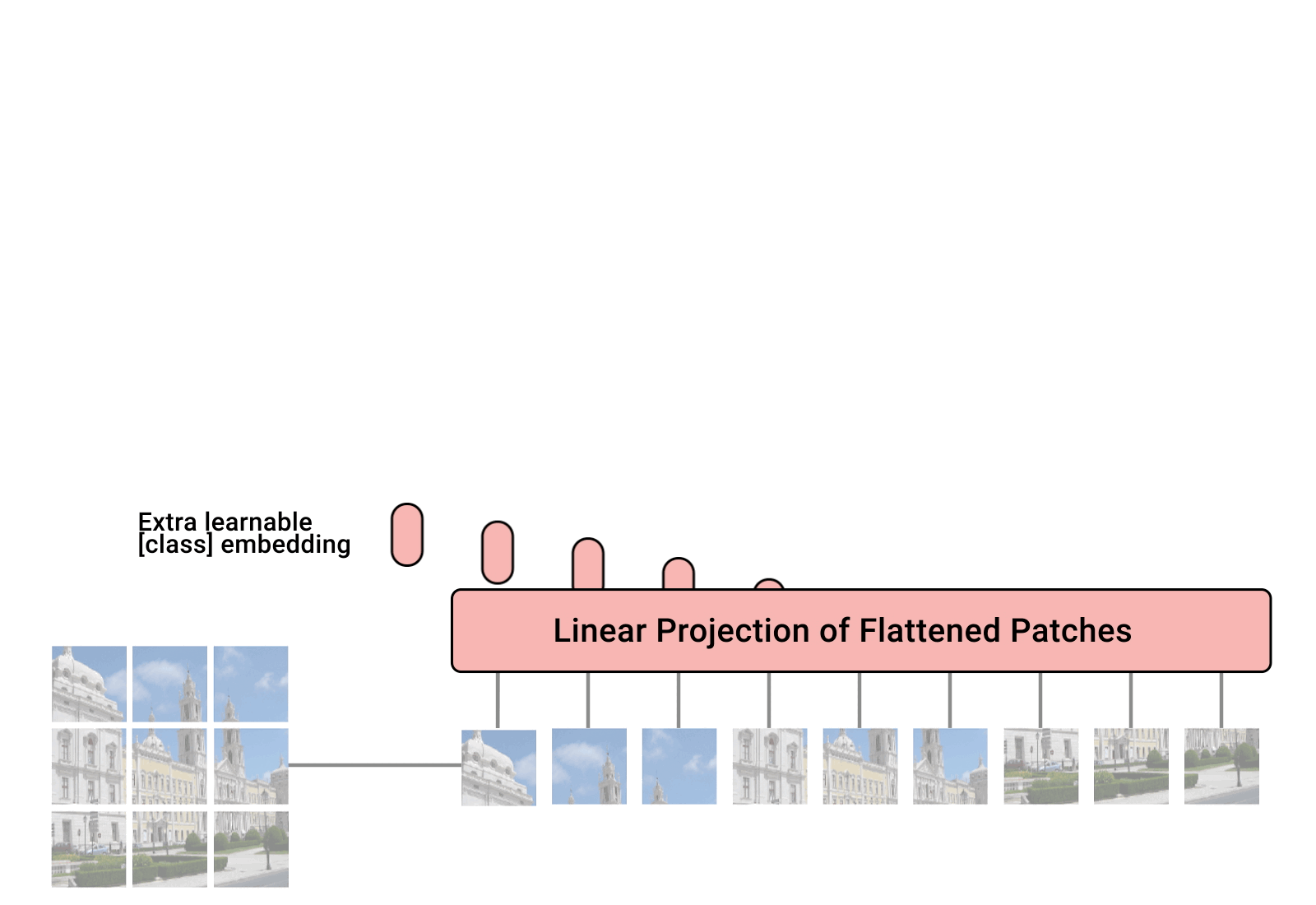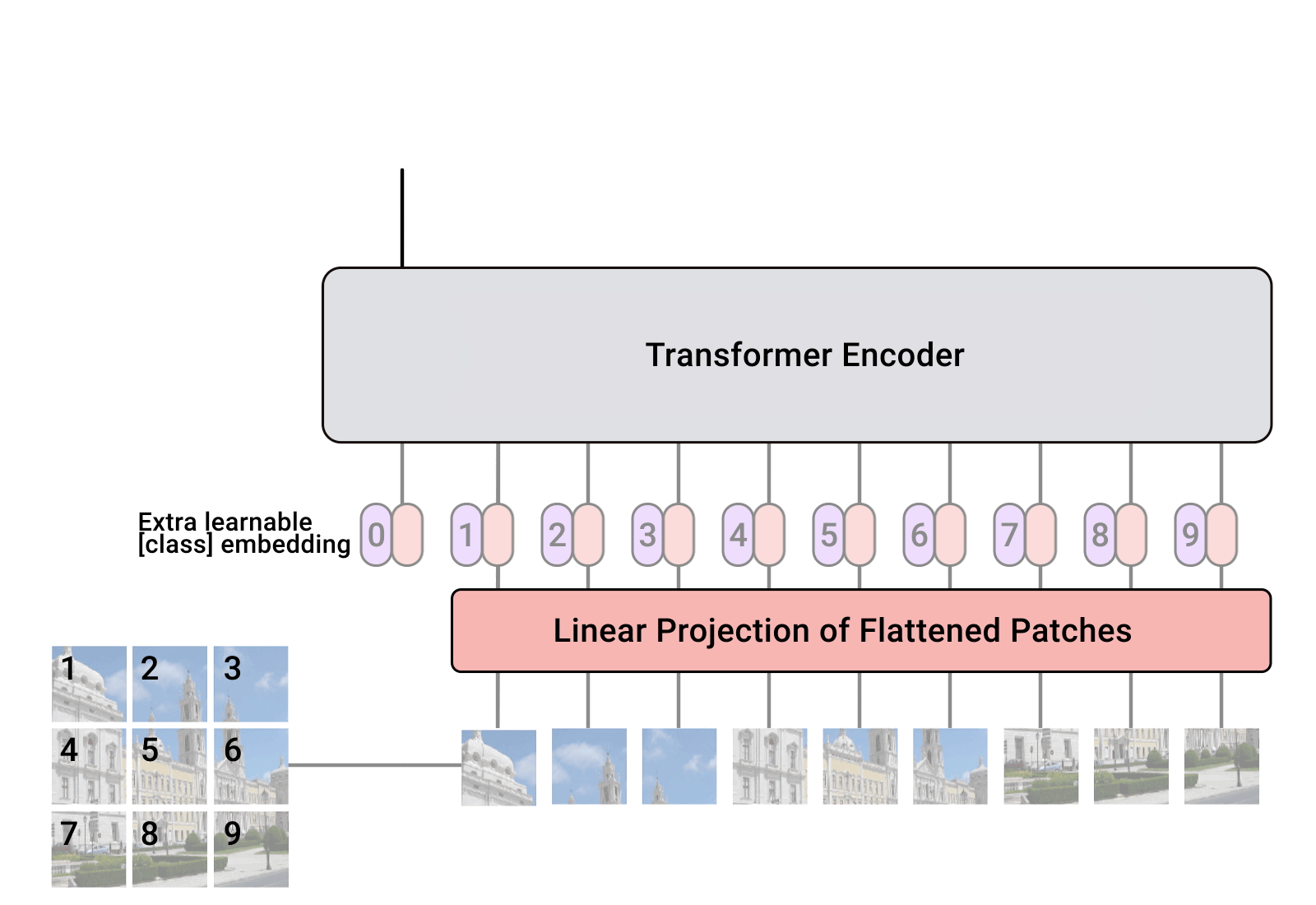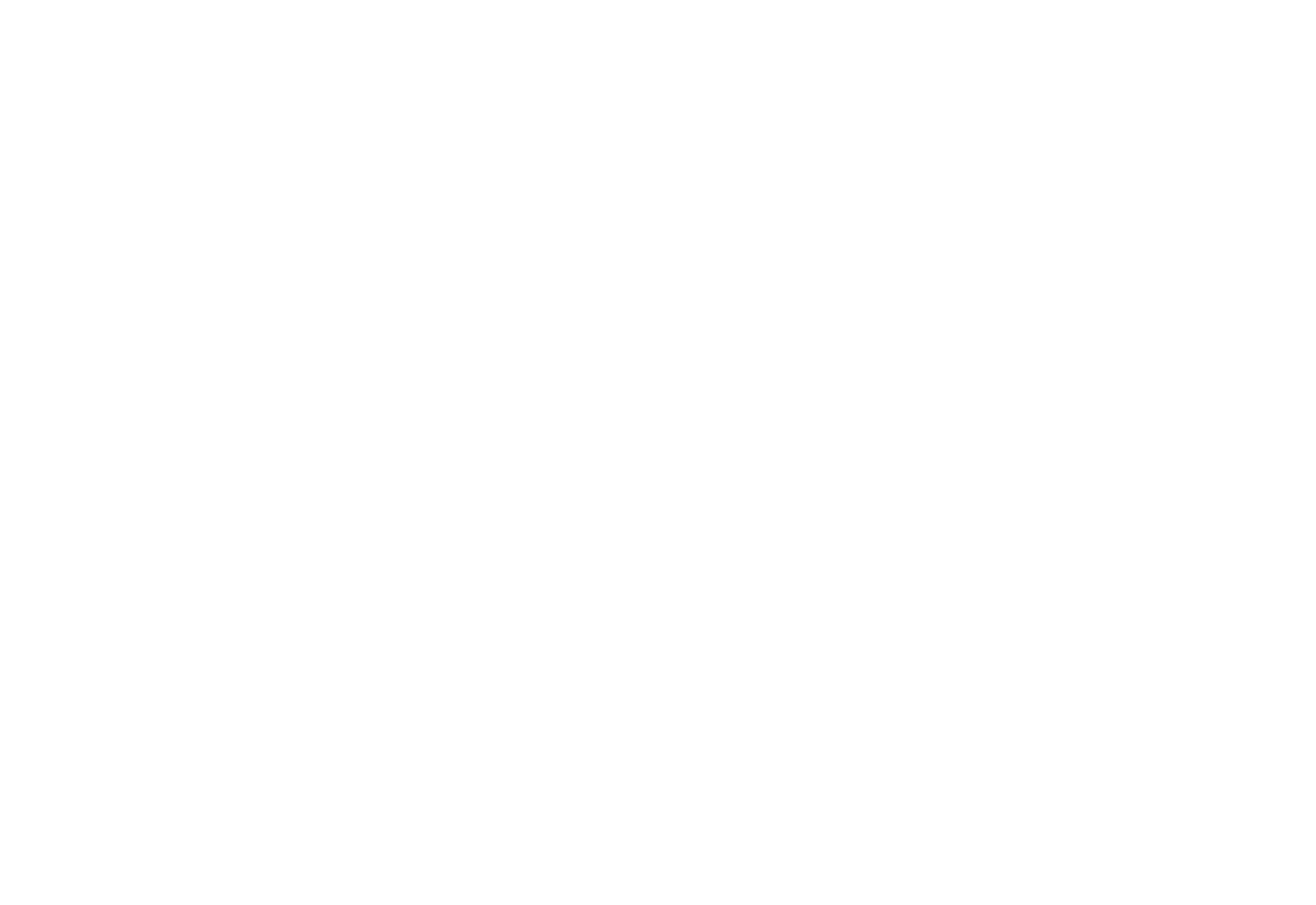The training data input is a 3rd-order tensor of size (48000, 28, 28), i.e. it consists of 48,000 images of size 28x28 pixels.
The labels for the training data are in a 48,000-dimensional vector containing the correct classes (“0”, “1”, …, “9”) for each training sample.
Convolutional neural network (CNN)
CNN is a type of deep learning model for processing data that has a grid pattern, such as images. They are very similar to any other neural network being built with neurons that have learnable weights and biases. Each neuron receives a input, then a dot product with the weights and bias followed with some non-linear operation. The network still represents a function mapping from raw input (pixels in case of images) to a class score. All is good for small resolution images. What happens when the image is 256x256x3 ? The very first hiddden layer in a fully connected neural network will have 196K parameters! So fully connected neural networks do not scale well for images.
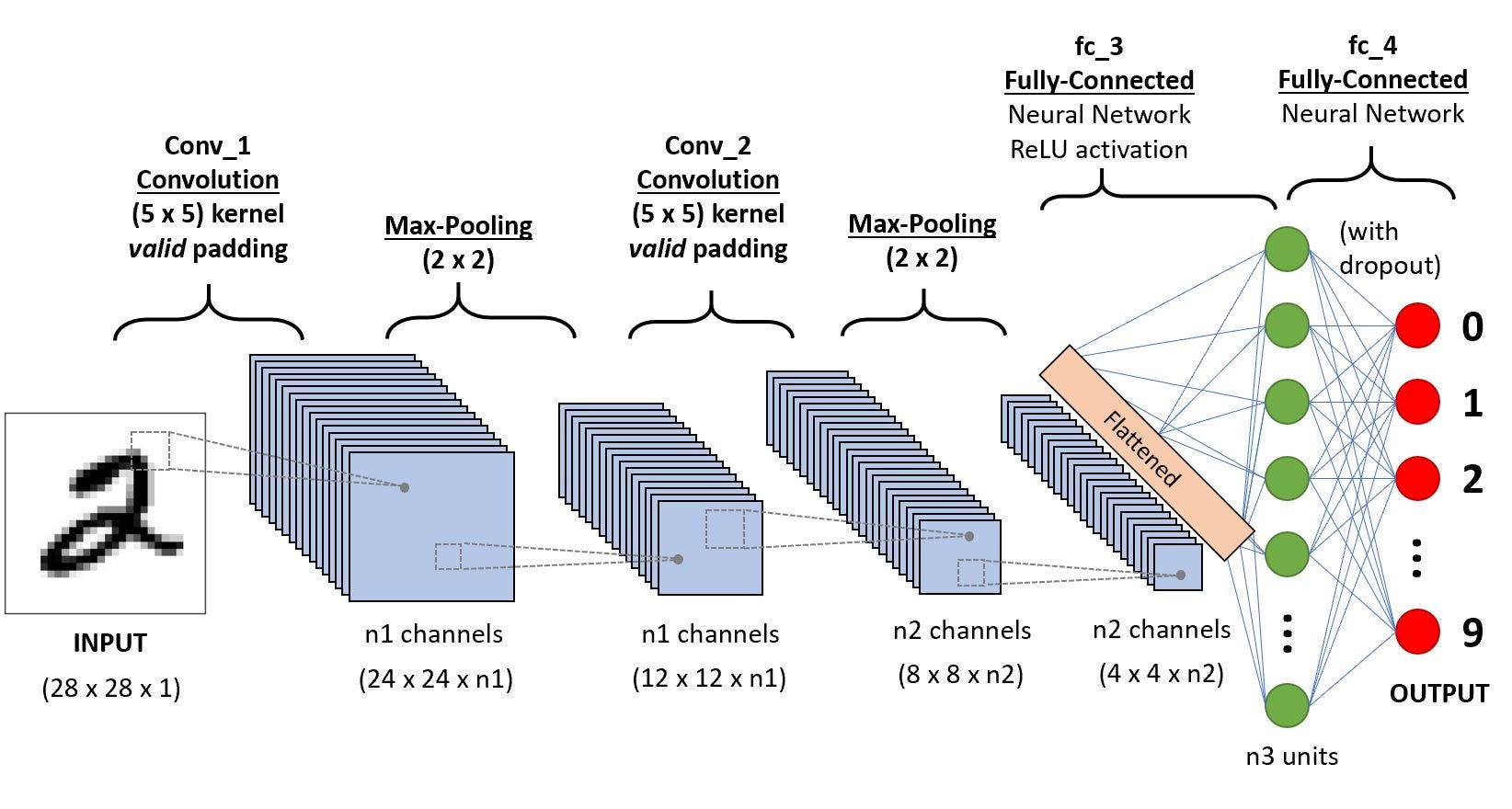
A typical convolutional neural network architecture consists of : * Convolutional Layer, * Pooling Layer, and * Fully-Connected Layer
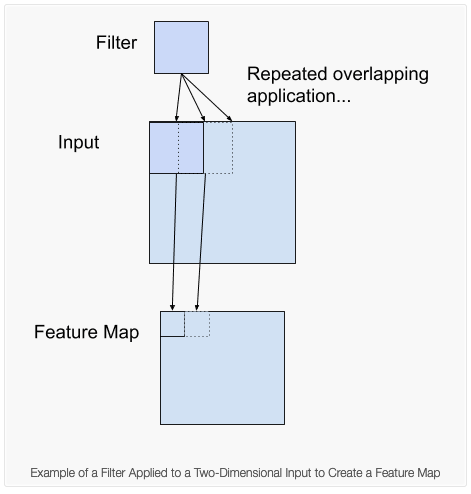
Figure 1: Convolutional Layer. Image credit: Sumit Saha
Let’s use a small model that includes convolutional layers
The Conv2d layers operate on 2D matrices so we input the digit images directly to the model.
The two Conv2d layers below learn 32 and 64 filters respectively.
They are learning filters for 3x3 windows.
The MaxPooling 2D layer reduces the spatial dimensions, that is, makes the image smaller.
It downsamples by taking the maximum value in the window
The pool size of 2 below means the windows are 2x2.
Helps in extracting important features and reduce computation
The Flatten layer flattens the 2D matrices into vectors, so we can then switch to Dense layers as in the MLP model.
class MNISTClassifier(nn.Module):def__init__(self):super().__init__()self.conv_1 = nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3)self.conv_2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3)self.drop_3 = nn.Dropout(p=0.25)self.dense_4 = nn.Linear(in_features=9216, out_features=128)self.drop_5 = nn.Dropout(p=0.5)self.dense_6 = nn.Linear(in_features=128, out_features=10)def forward(self, inputs): x =self.conv_1(inputs) x = nn.functional.relu(x) x =self.conv_2(x) x = nn.functional.relu(x) x = nn.functional.max_pool2d(x, kernel_size=2) x =self.drop_3(x) x = torch.flatten(x, start_dim=1) x =self.dense_4(x) x = nn.functional.relu(x) x =self.drop_5(x) x =self.dense_6(x) x = nn.functional.softmax(x, dim=1)return x
Convolutional Basics
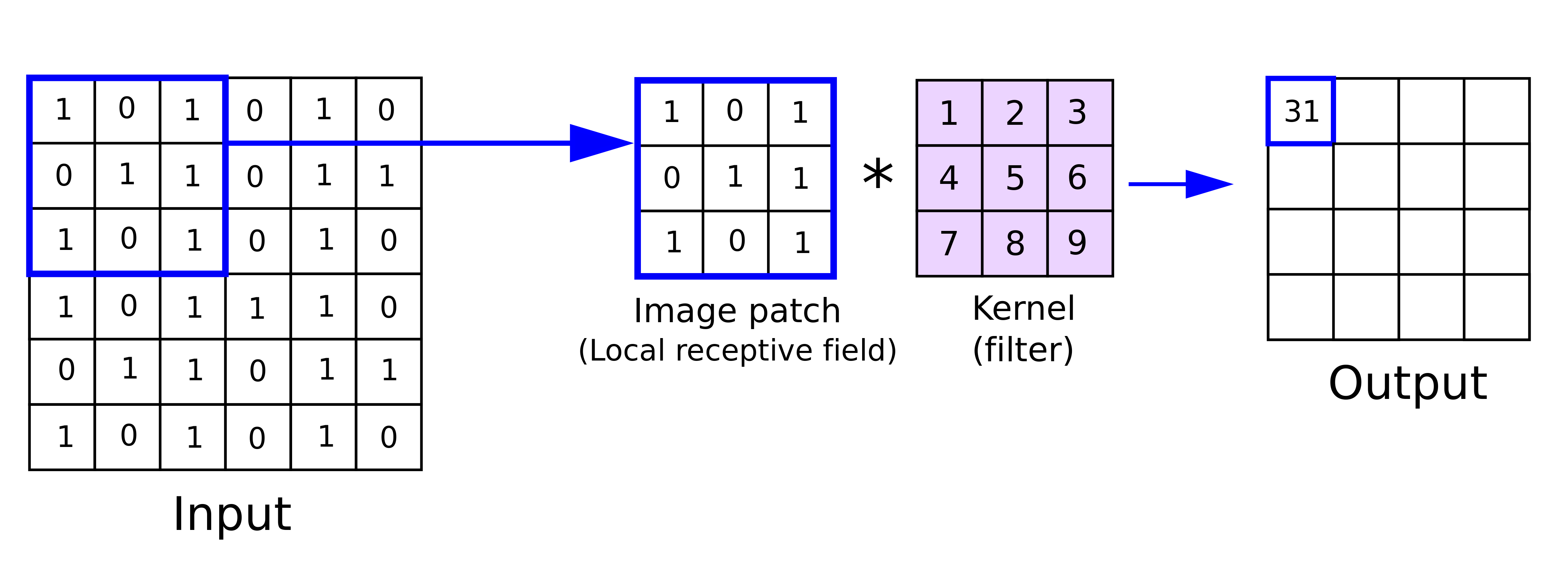
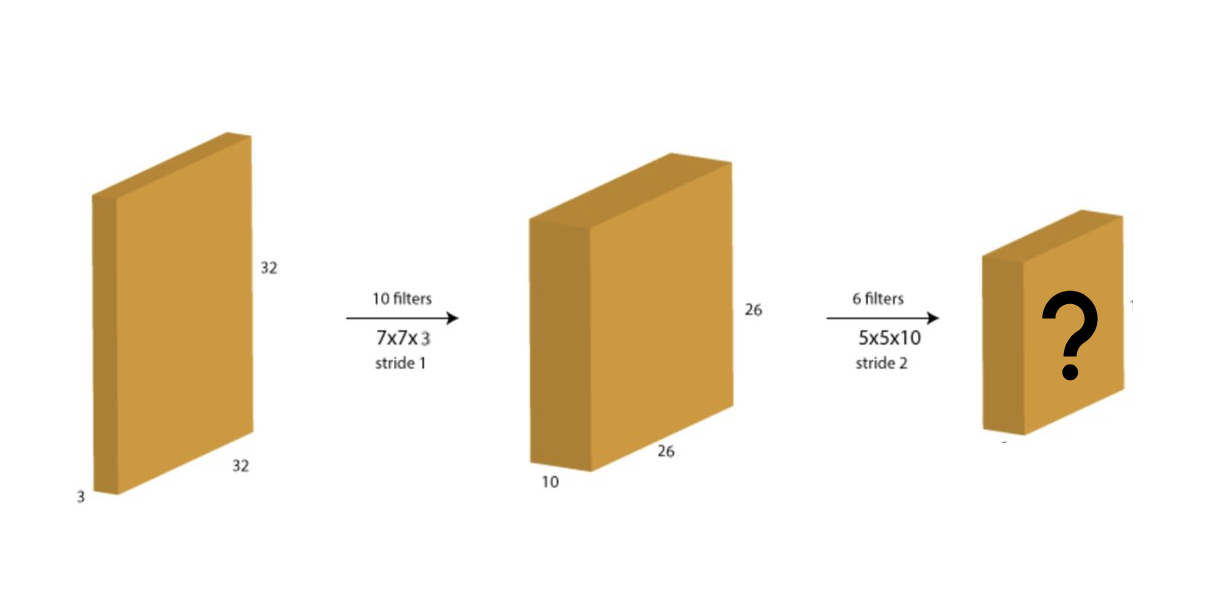
A convolution layer is formed by convolving a filter (usually 5x5 or 3x3) repeatedly over the input image to create a feature map, meaning the filter slides over spatially from the top left corner of the image to the bottom right corner of the image. Filters learn different features and detect the patterns in an image.
N = dimension of the input image. (ex, for an image of 28x28x1, N=28)
F = dimension of the filter (F=3 for a filter of 3x3)
S = Stride value
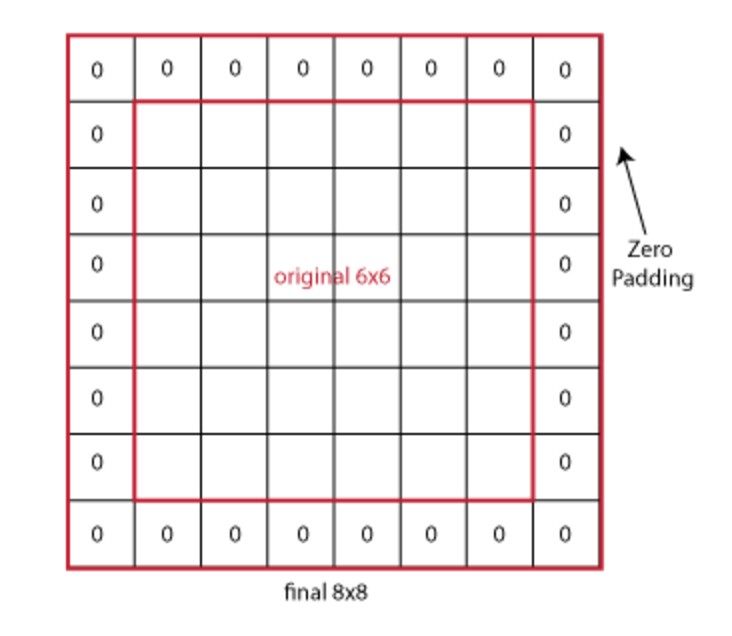
P = Size of the zero padding used
Max Pooling
Pooling reduces the dimensionality of the images, with max-pooling being one of the most widely used.
Figure 5
Multiple Channels
Usually colored images have multiple channels with RGB values. What happens to the filter sizes and activation map dimensions in those cases?
Figure 6
Visualizing learned features from CNNs
The filters from the initial hidden layers tend to learn low level features like edges, corners, shapes, colors etc. Filters from the deeper layers tend to learn high-level features detecting patterns like wheel, car, etc.
Figure 7
Now we can train the network, similarly to the previous notebook.
def train_one_epoch(dataloader, model, loss_fn, optimizer): model.train()for batch, (X, y) inenumerate(dataloader):# forward pass pred = model(X) loss = loss_fn(pred, y)# backward pass calculates gradients loss.backward()# take one step with these gradients optimizer.step()# resets the gradients optimizer.zero_grad()
def evaluate(dataloader, model, loss_fn):# Set the model to evaluation mode - some NN pieces behave differently during training model.eval() size =len(dataloader.dataset) num_batches =len(dataloader) loss, correct =0, 0# We can save computation and memory by not calculating gradients here - we aren't optimizingwith torch.no_grad():# loop over all of the batchesfor X, y in dataloader: pred = model(X) loss += loss_fn(pred, y).item()# how many are correct in this batch? Tracking for accuracy correct += (pred.argmax(1) == y).type(torch.float).sum().item() loss /= num_batches correct /= size accuracy =100* correctreturn accuracy, loss
def train_network(batch_size, epochs, lr): cnn_model = MNISTClassifier() train_dataloader = torch.utils.data.DataLoader(training_data, batch_size=batch_size) val_dataloader = torch.utils.data.DataLoader(validation_data, batch_size=batch_size) optimizer = torch.optim.Adam(cnn_model.parameters(), lr=lr) loss_fn = nn.CrossEntropyLoss() history = numpy.zeros((epochs, 4))for j inrange(epochs): train_one_epoch(train_dataloader, cnn_model, loss_fn, optimizer)# checking on the training & val loss and accuracy once per epoch acc_train, loss_train = evaluate(train_dataloader, cnn_model, loss_fn) acc_val, loss_val = evaluate(val_dataloader, cnn_model, loss_fn)print(f"Epoch {j}: val. loss: {loss_val:.4f}, val. accuracy: {acc_val:.4f}") history[j, :] = [acc_train, loss_train, acc_val, loss_val]return history, cnn_model
Epoch 0: val. loss: 1.4972, val. accuracy: 96.3750
Epoch 1: val. loss: 1.4928, val. accuracy: 96.8667
2: val. loss: 1.4946, val. accuracy: 96.6833
CPU times: user 4min 21s, sys: 57.4 s, total: 5min 19s
Wall time: 2min 3s
The model should be better than the non-convolutional model even if you’re only patient enough for three epochs.
You can compare your result with the state-of-the art here. Even more results can be found here.
Advanced networks
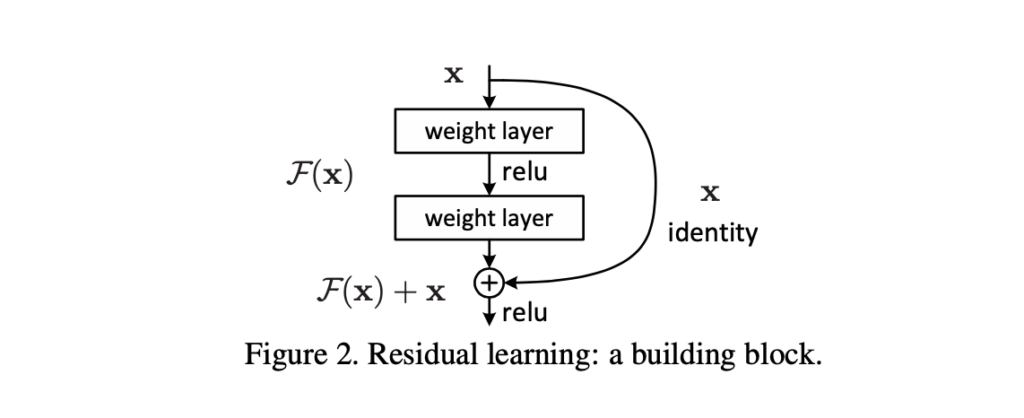
ResNet
Deeper and deeper networks that stack convolutions end up with smaller and smaller gradients in early layers. ResNets use additional skip connections where the output layer is f(x) + x instead of f(w x + b) or f(x). This avoids vanishing gradient problem and results in smoother loss functions. Refer to the ResNet paper and ResNet loss visualization paper for more information.
U-NET is a convolution based neural network architecture orginally developed for biomedical image segmentation tasks. It has an encoder-decoder architecture with skip connections in between them.
You’ll learn about language models today, which use “transformer” models. There has been some success applying transformers to images (“vision transformers”). To make images sequential, they are split into patches and flattened. Then apply linear embeddings and positional embeddings and feed it to a encoder-based transformer model.