---
title: "Example: Linear Regression"
description: "Simple example illustrating how to train a linear regression model using stochastic gradient descent (SGD) on a dataset of house prices."
categories:
- ai
- hpc
- ai4science
date: '2025-07-15'
date-modified: last-modified
format:
ipynb:
default-image-extension: svg
html: default
gfm:
toc: true
author:
- id: sf
name: Sam Foreman
orcid: 0000-0002-9981-0876
email: foremans@anl.gov
affiliation:
- name: '[ANL](https://www.anl.gov/)'
city: Lemont
state: IL
url: https://alcf.anl.gov/about/people/sam-foreman
- id: hz
name: Huihuo Zheng
# orcid: 0000-0002-9981-0876
email: huihuo.zheng@anl.gov
affiliation:
- name: '[ANL](https://www.anl.gov/)'
city: Lemont
state: IL
url: https://alcf.anl.gov/about/people/huihuo-zheng
---
[](https://colab.research.google.com/github/saforem2/intro-hpc-bootcamp-2025/blob/main/docs/00-intro-AI-HPC/6-linear-regression/index.ipynb) [](https://github.com/saforem2/intro-hpc-bootcamp-2025/blob/main/docs/00-intro-AI-HPC/6-linear-regression/README.md)
In this notebook, we will talk about:
- What is AI training?
- How does large language model work?
- A simple AI model: linear regression
<details closed><summary><h2>ALCF Specific Setup</h2></summary>
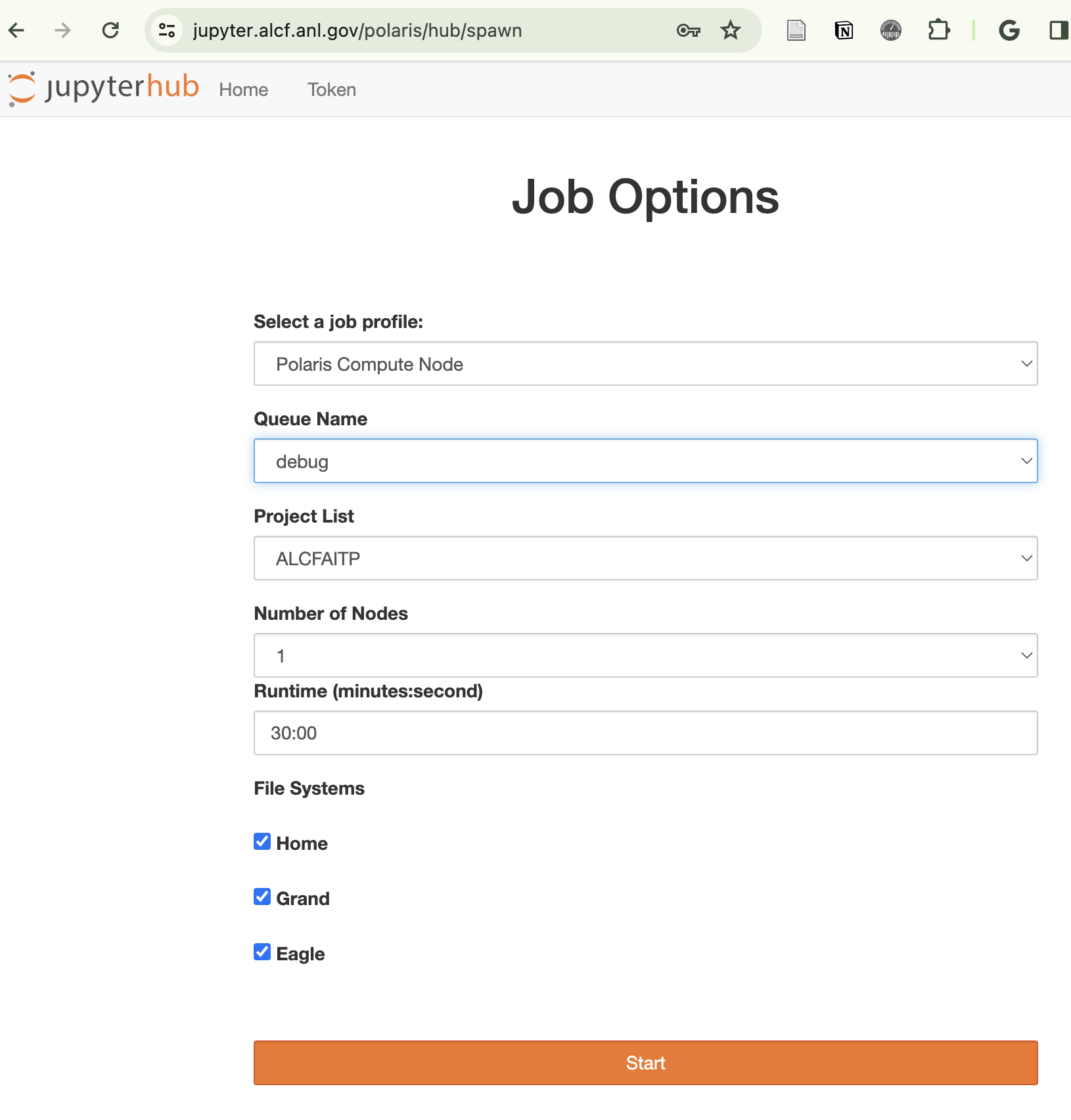
## How to run this notebook on Polaris
- Go to <https://jupyter.alcf.anl.gov>, and click "Login Polaris"
- After login, select `ALCFAITP` project and `ALCFAITP` queue during the
lecture (use `debug` queue outside of the lecture)
- Load the notebook and select "datascience/conda-2023-01-10" python kernel
::: {#fig-jupyter}

:::
**How to run this notebook on Google Colab**
- Go to https://colab.research.google.com/, sign in or sign up
- "File"-> "open notebook"
- Choose `01_intro_AI_on_Supercomputer/01_linear_regression_sgd.ipynb` from the list
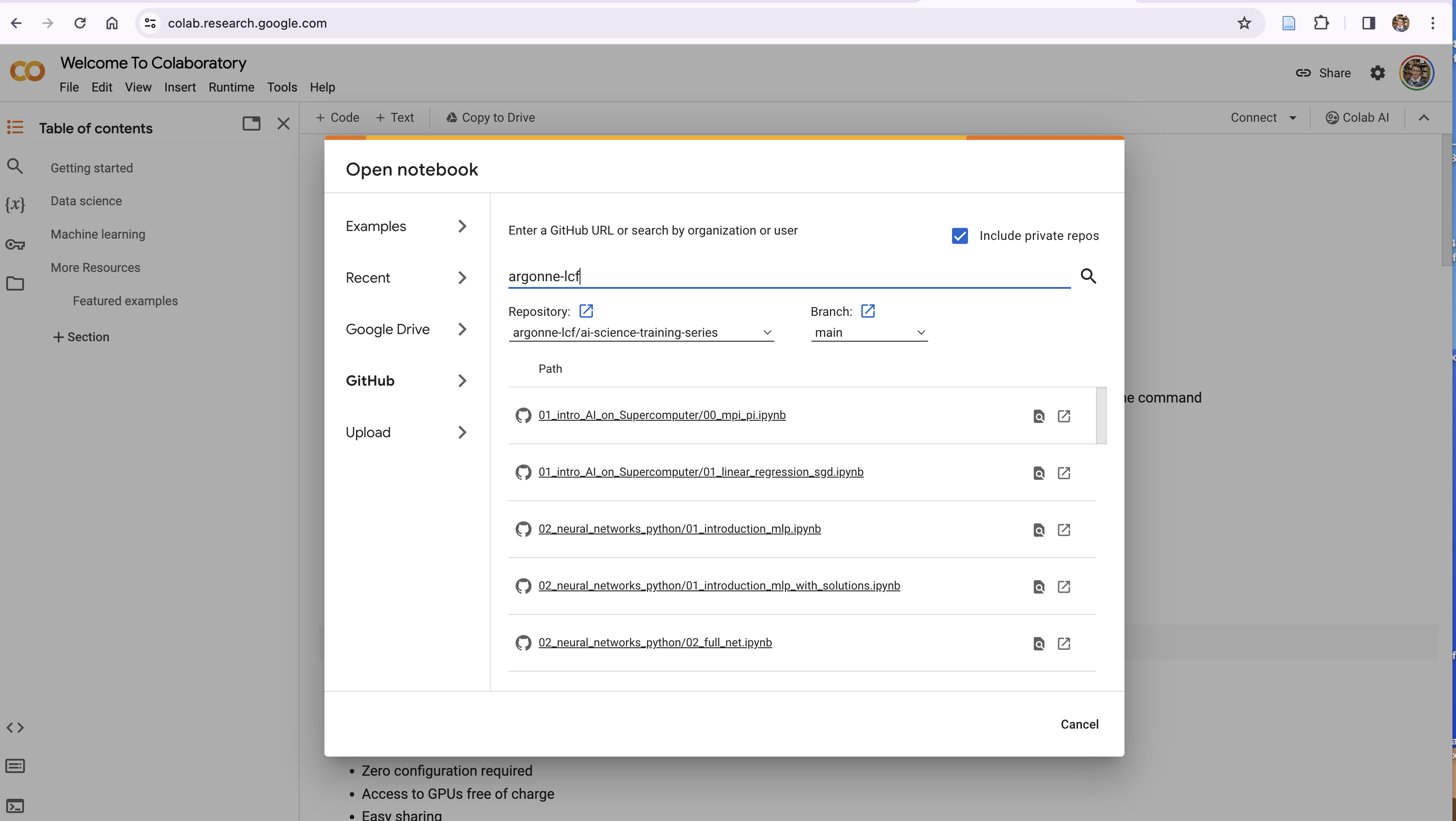
</details>
## What is AI training?
**Two ways of learning English**:
- through learning rules;
- through hearing a lot of speakings
::: {#fig-data-driven}
{width="90%"}
Data Driven Learning
:::
I learned English in my middle school, and memorized a lot of grammar rules in
my mind.
Every time when I speak, I try to follow the grammar rules as much as I can.
But I always break the rules.
However, my daugher learned English differently.
She learns speaking by hearing a lot of speaking from TV, teachers, classmates,
and her older brother.
The fact is that, she seldomly breaks grammar rules. This way of learning by
observing patterns is very powerful! This is the essence of AI or data driven
science.
## How does large language model work?
Large Language Models, like GPT, function by pre-training on extensive datasets
to learn language patterns, utilizing transformer architecture for contextual
understanding, and can be fine-tuned for specific tasks, enabling them to
generate coherent and contextually relevant text based on provided inputs.
::: {#fig-llm}
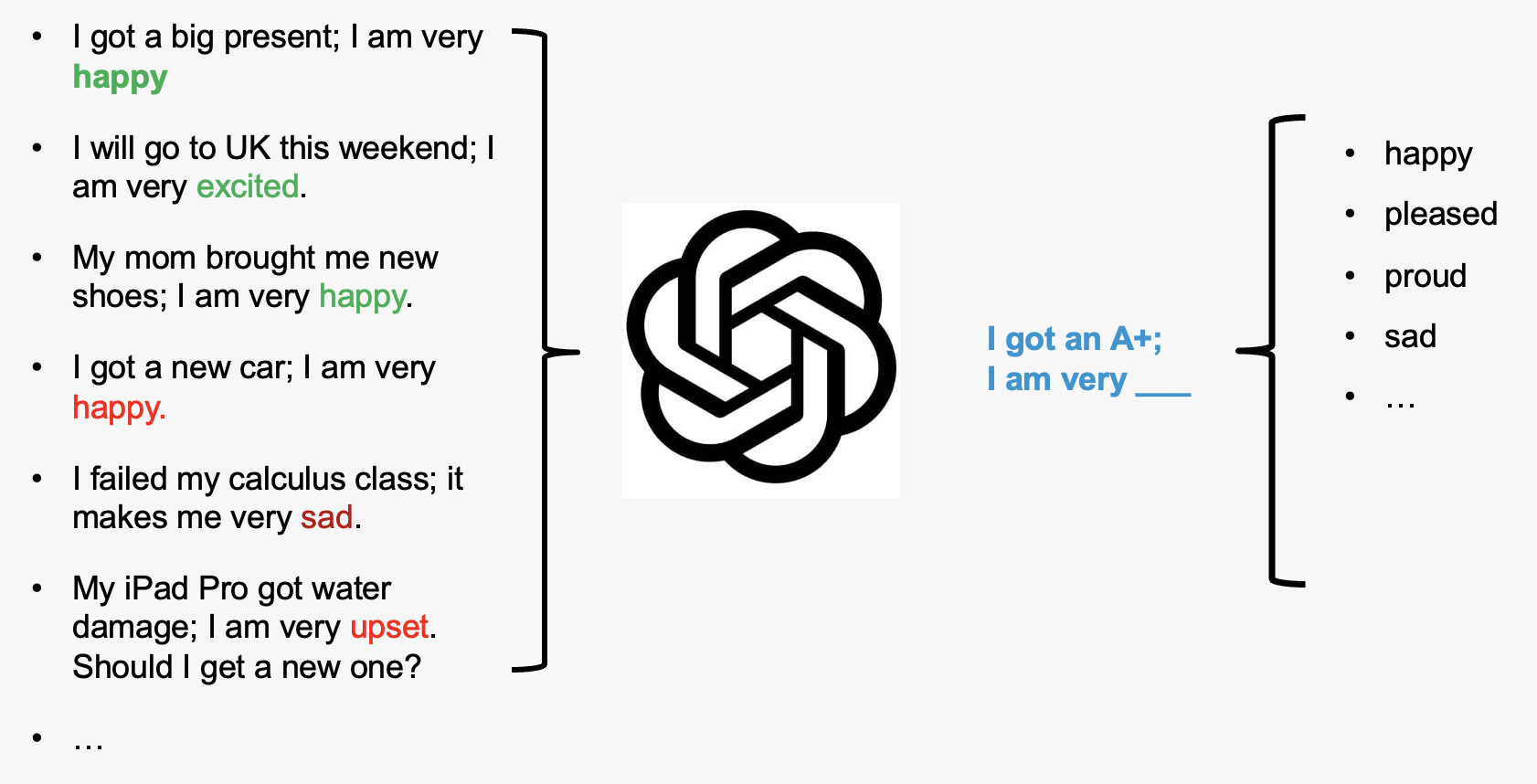

:::
**More complicated example**:
::: {.flex-container}
::: {.flex-item style="width:43%"}

:::
::: {.flex-item style="width:49.2%"}

:::
:::
You can do this on https://chat.openai.com
## Simplest AI model example: linear regression
This example is adopted from Bethany Lusch, ALCF.
Linear regression is the simplest example learning from existing data for
future prediction.
::: {#fig-excel-linear-regression}
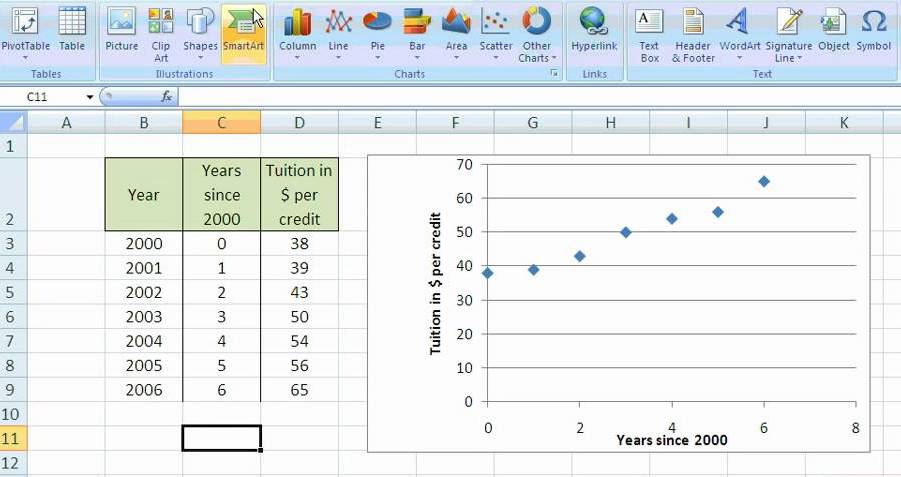
Linear regression in Excel
:::
We're going to review the math involved in this process to help understand how
training an AI works.
First we will load some tools that others wrote and we can use to help us work.
- [Pandas](https://pandas.pydata.org/docs/): a toolkit for working with row vs.
column data, like excel sheets, and CSV (Comma Seperated Values) files.
- [Numpy](https://numpy.org/doc/): a toolkit for managing arrays, vectors,
matrices, etc, doing math with them, slicing them up, and many other handy
things.
- [Matplotlib](https://matplotlib.org/stable/index.html): a toolkit for
plotting data
```{python}
import os
os.environ["FORCE_COLOR"] = "1"
os.environ["TTY_INTERACTIVE"] = "1"
import ambivalent
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use(ambivalent.STYLES['ambivalent'])
sns.set_context("notebook")
plt.rcParams["figure.figsize"] = [6.4, 4.8]
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import IPython.display as ipydis
import time
import ezpz
from rich import print
```
### Dataset
We used a realestate dataset from Kaggle to produce this reduced dataset.
This dataset contains the _sale price_ and _above ground square feet_ of many
houses.
We can use this data for our linear regression.
We use Pandas to read the data file which is stored as Comma Separated Values
(CSV) and print the column labels.
CSV files are similar to excel sheets.
```{python}
! [ -e ./slimmed_realestate_data.csv ] || wget https://raw.githubusercontent.com/argonne-lcf/ai-science-training-series/main/01_intro_AI_on_Supercomputer/slimmed_realestate_data.csv
data = pd.read_csv('slimmed_realestate_data.csv')
print(data.columns)
```
Now pandas provides some helpful tools for us to inspect our data.
It provides a `plot()` function that, behind the scenes, is calling into the
_Matplotlib_ library and calling the function
[matplotlib.pyplot.plot()](https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.plot.html).
In this case, we simply tell it the names of the columns we want as our _x_ and
_y_ values and the `style` (`'.'` tells `matplotlib` to use a small dot to
represent each data point).
```{python}
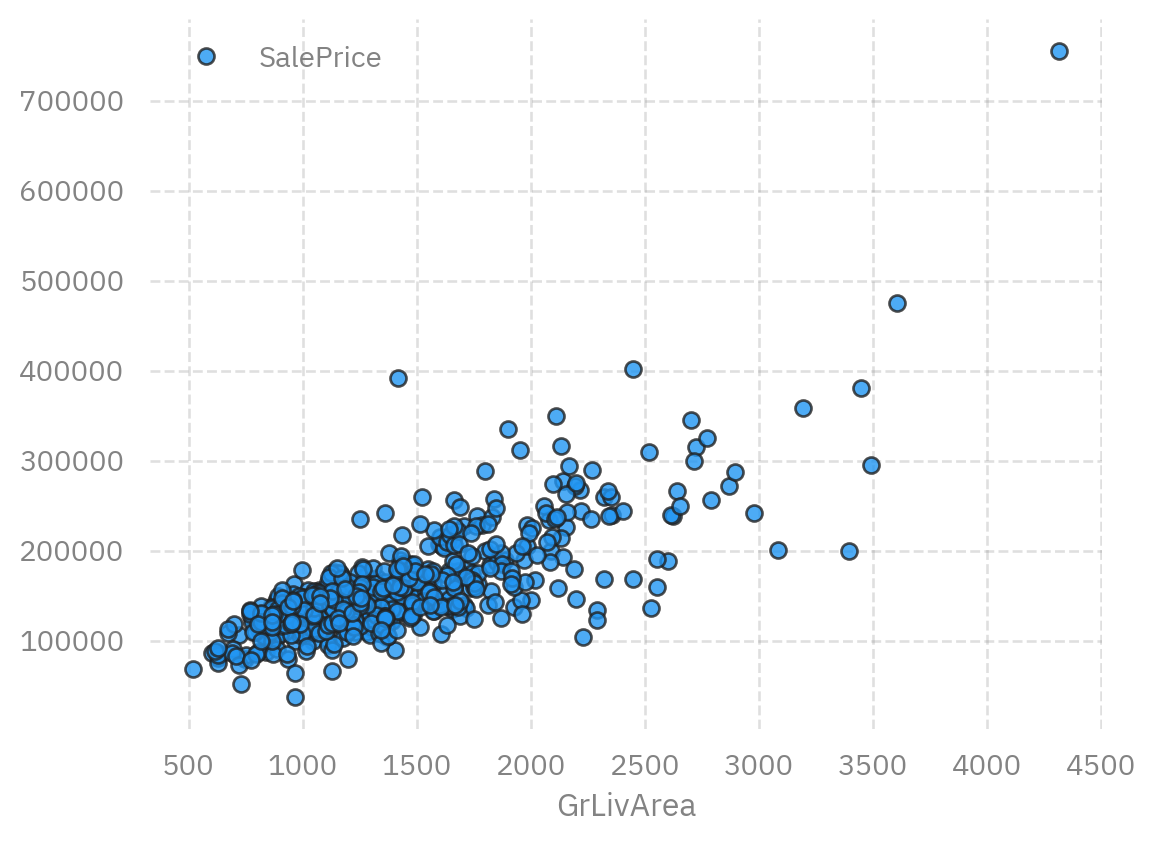
data.plot(x='GrLivArea', y='SalePrice',style='o', alpha=0.8, markeredgecolor="#222")
```
or, even better yet, use [`seaborn`](https://seaborn.pydata.org/) to plot the
data:
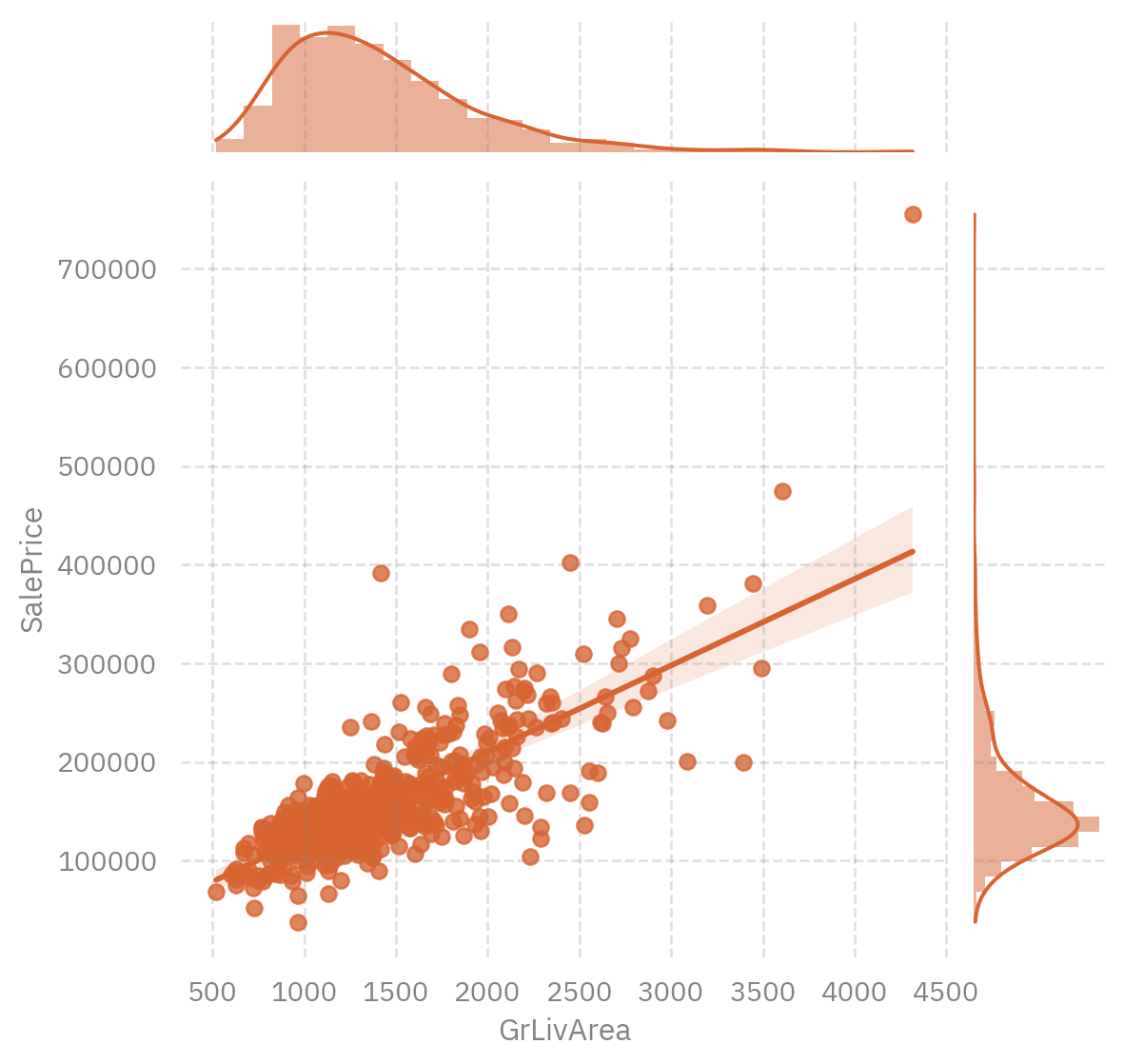
```{python}
sns.jointplot(
x="GrLivArea",
y="SalePrice",
data=data,
kind='reg',
color=(216 / 255.0, 100 / 255.0, 50 / 255.0, 0.33),
)
```
### Theory of linear regression
The goal of learning regression is to find a line that is closest to all the points.
The slope and intercept of such a line $y = m x + b$ can be found as:
$$m = { n (\Sigma xy) - (\Sigma x) (\Sigma y) \over n (\Sigma x^2) - (\Sigma x)^2 } $$
$$b = { (\Sigma y) (\Sigma x^2) - (\Sigma x) (\Sigma xy) \over n (\Sigma x^2) - (\Sigma x)^2 } $$
Details derivation of this can be found [here](https://en.wikipedia.org/wiki/Simple_linear_regression).
We'll break this calculation into a few steps to help make it easier.
First lets define $x$ and $y$. $x$ will be our _above ground square footage_
and $y$ will be _sale price_.
In our equations we have a few different values
we need, such as $n$ which is just the number of points we have:
```{python}
n = len(data)
```
Then we need our $x$ and $y$ by selecting only the column we care about for
each one.
Note about data formats: `data` is a Pandas
[DataFrame](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.html#pandas.DataFrame)
object which has rows and columns; `data['GrLivArea']` is a Pandas
[Series](https://pandas.pydata.org/docs/reference/api/pandas.Series.html)
object which only has rows; then we also convert from _Pandas_ data formats (in
this case a _Series_) to _Numpy_ data formats using the `to_numpy()` function
which is part of the Pandas _Series_ object.
```{python}
x = data['GrLivArea'].to_numpy()
y = data['SalePrice'].to_numpy()
```
Now we will calculate $\Sigma xy$, $\Sigma x$, $\Sigma y$, and $\Sigma x^2$:
```{python}
sum_xy = np.sum(x*y)
sum_x = np.sum(x)
sum_y = np.sum(y)
sum_x2 = np.sum(x*x)
```
The denominator in the equation for $m$ and $b$ are the same so we can
calculate that once:
```{python}
denominator = n * sum_x2 - sum_x * sum_x
```
Then we can calculate our fit values:
```{python}
m = (n * sum_xy - sum_x * sum_y) / denominator
b = (sum_y * sum_x2 - sum_x * sum_xy) / denominator
print('y = %f * x + %f' % (m,b))
# saving these for later comparison
m_calc = m
b_calc = b
```
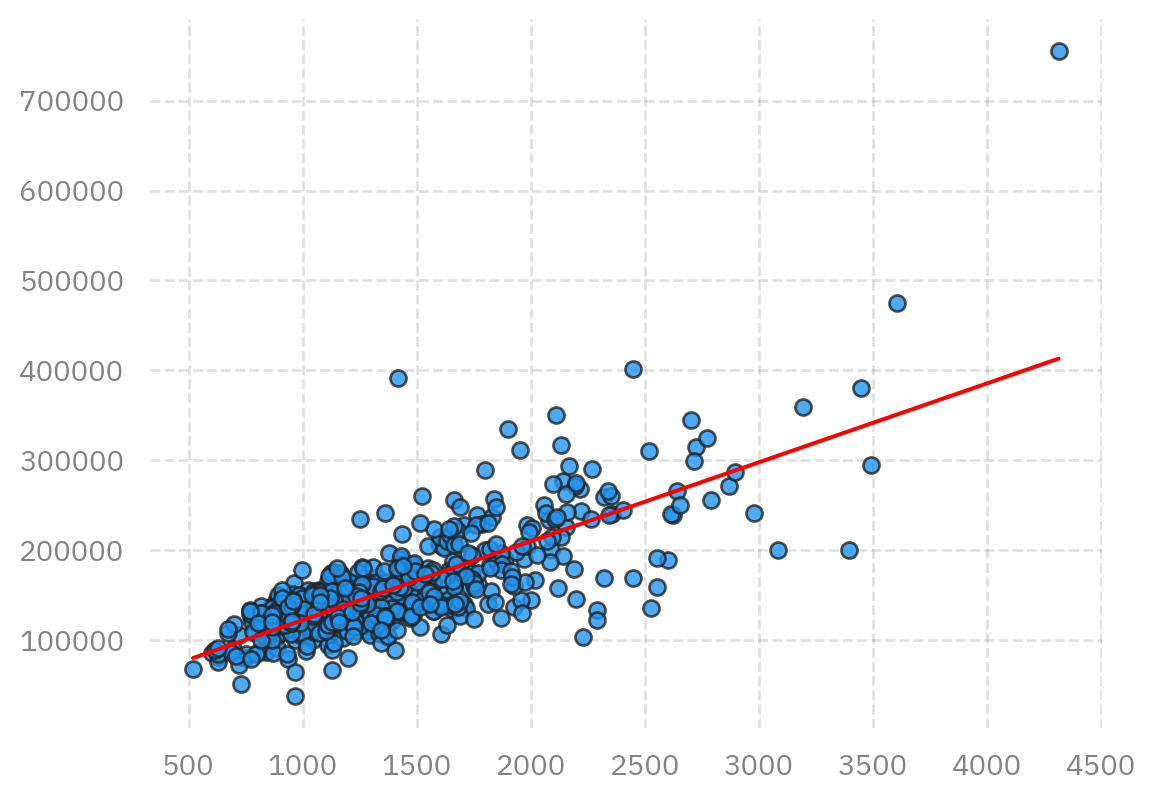
Now we can plot the fit results with our data to see how we did.
First we define a plotting function because we're going to do this often and we
want to reuse our code:
```{python}
def plot_data(x,y,m,b,plt = plt):
# plot our data points with 'bo' = blue circles
plt.plot(x, y, 'o', alpha=0.8, markeredgecolor="#222")
# create the line based on our linear fit
# first we need to make x points
# the 'arange' function generates points between two limits (min,max)
linear_x = np.arange(x.min(),x.max())
# now we use our fit parameters to calculate the y points based on our x points
linear_y = linear_x * m + b
# plot the linear points using 'r-' = red line
plt.plot(linear_x, linear_y, 'r-', label='fit')
```
Now can use this function to plot our results:
```{python}
plot_data(x,y,m,b)
```
### Training through Stochastic Gradient Descent (SGD)
SGD is a common method in AI for training deep neural networks on large
datasets.
It is an iterative method for optimizing a loss function that we get
to define.
We will use this simple linear regression to demonstrate how it
works.
#### The model
In AI, neural networks are often referred to as a _model_ because, once fully
trained, they should model (AKA predict) the behavior of our system.
In our example, the system is how house prices vary based on house size.
We know our system is roughly driven by a linear function:
$$\hat{y_i}(x_i) = m * x_i + b $$
We just need to figure out $m$ and $b$. Let's create a function that calculates
our model given $x$, $m$, and $b$.
```{python}
def model(x,m,b):
return m * x + b
```
#### The Loss Function
A _loss function_, or _objective function_, is something we define and is based
on what we want to achieve.
In the method of SGD, it is our goal to minimize (or make close to zero) the
values calculated from the _loss function_.
In our example, we ideally want the prediction of our _model_ to be equal to
the actual data, though we will settle for "as close as possible".
So we will select our _loss function_ to be the [Mean Squared Error](https://en.wikipedia.org/wiki/Mean_squared_error) function:
$$ L(y_i,\hat{y_i}) = (y_i - \hat{y_i}(x_i))^2 $$
where $y_i$ is our $i^{th}$ entry in the `data['SalePrice']` vector and
$\hat{y_i}$ is the prediction based on evaluting $m * x_i + b$.
This function looks like the figure below when we plot it with
$x=y_i - \hat{y_i}(x_i)$
and we we want to be down near
$y_i - \hat{y_i}(x_i) = 0$
which indicates that our $y_i$ is as close as possible to $\hat{y_i}$.
::: {#fig-loss-func}
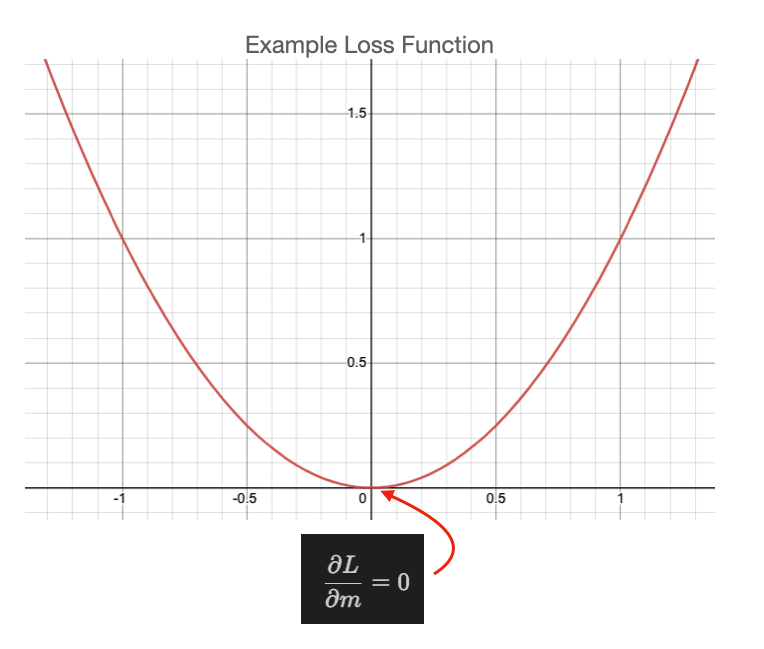
Loss function for linear regression
:::
Here we crate a function that calculates this for us.
```{python}
def loss(x,y,m,b):
y_predicted = model(x,m,b)
return np.power( y - y_predicted, 2 )
```
#### Minimizing the Loss Function
We want to use the loss function in order to guide how to update $m$ and $b$ to
better model our system.
In calculus we learn to minimize a function with
respect to a variable you calculate the _partial derivative_ with respect to
the variable you want to vary.
$$ { \partial L \over \partial m } = 0 $$
The location of the solution to this is the minimum as shown in the figure
above.
We can write down the partial derivative of the loss function as:
$$ { \partial L \over \partial m } = -2 x_i (y_i - \hat{y_i}(x_i)) $$
$$ { \partial L \over \partial b } = -2 (y_i - \hat{y_i}(x_i)) $$
We can use this to calculate an adjustment to $m$ and $b$ that will reduce the
loss function, effectively improving our fitting parameters.
This is done using this equation:
$$ m' = m - \eta { \partial L \over \partial m }$$
$$ b' = b - \eta { \partial L \over \partial b }$$
Here our original $m$ and $b$ are adjusted by the partial derivative multiplied
by some small factor, $\eta$, called the _learning rate_. This learning rate is
very important in our process and must be tuned for every problem.
In our example, the selection of the learning rate essentially defines how
close we can get to the minimum, AKA the best fit solution.
This figure shows
what happens when we pick a large learning rate.
We first select a starting
point in our loss function (typically randomly), then every update from $m$/$b$
to $m'$/$b'$ results in a shift to somewhere else on our loss function
(following the red arrows).
In this example, our learning rate ($\eta$) has
been selected too large such that we bounce back and forth around the minimum,
never reaching it.
::: {#fig-parabola-largeLR}
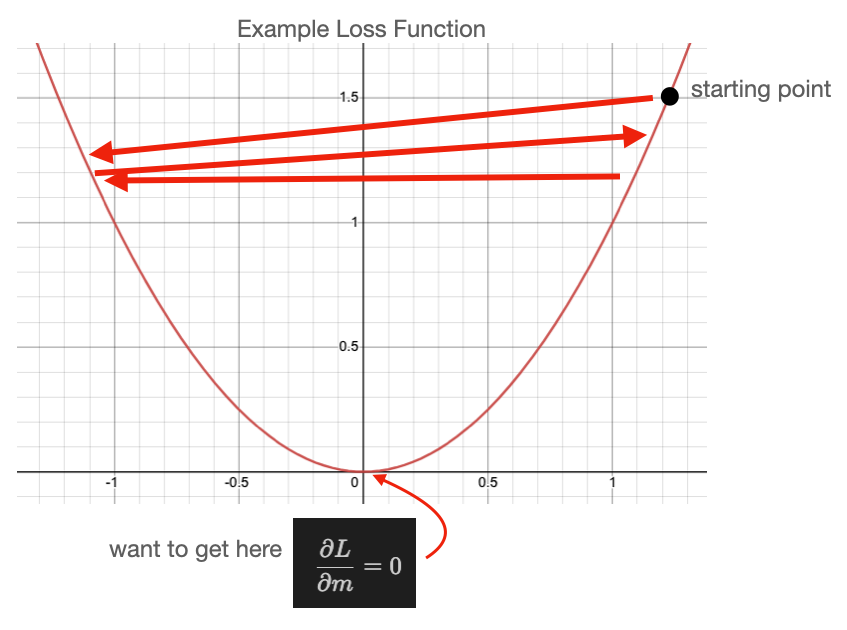
Large LR
:::
If we select a smaller learning we can see better behavior in the next figure.
::: {#fig-parabola-smallLR}
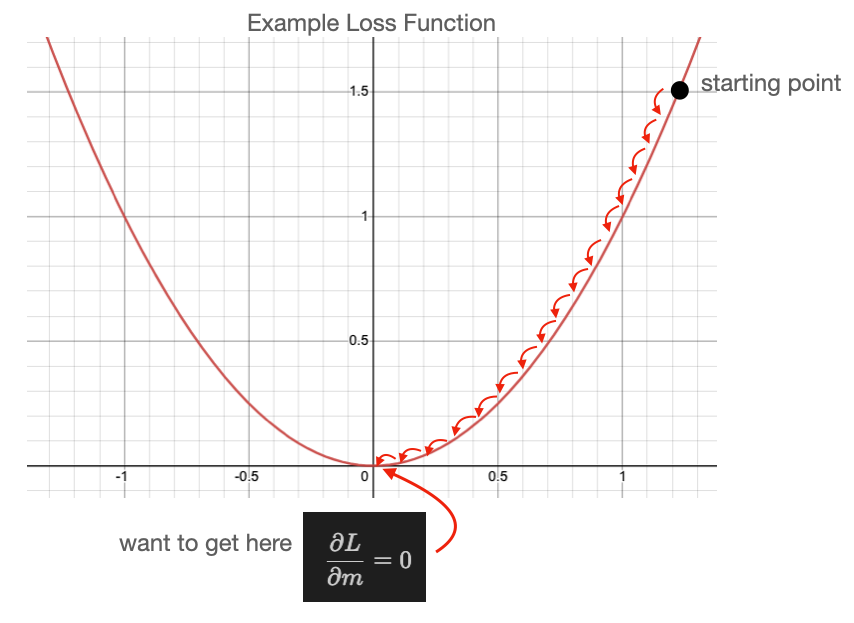
Small LR
:::
Though, keep in mind, too small a learning rate results is so little progress
toward the minimum that you may never reach it!
A pit fall of SGD that one must be aware of is when your loss function is
complex, with many minima.
The next figure shows such a case, in which we
select a small learning rate and our starting point happens to be near a local
minimum that is not the lowest minimum.
As shown, we do reach a minimum, but it
isn't the lowest minimum in our loss function.
It could be that we randomly
select a starting point near the minimum we care about, but we should build
methods that are more robust against randomly getting the right answer.
::: {#fig-local-min-smallLR}
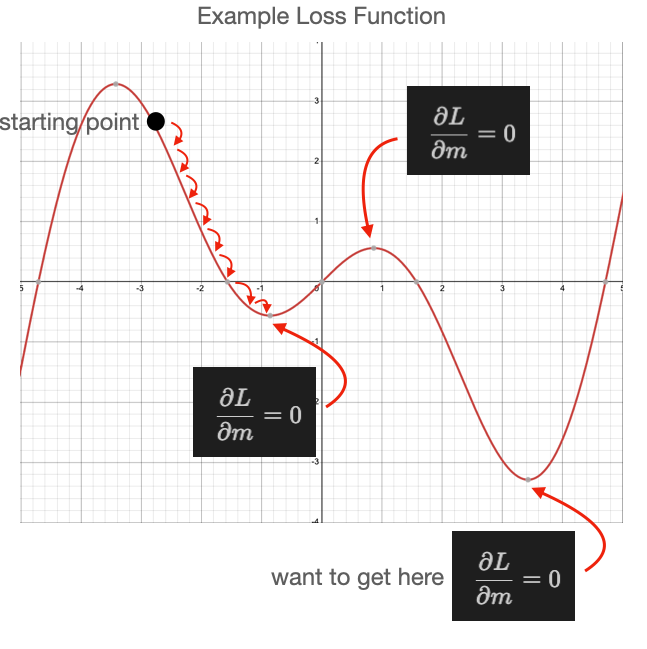
Local minimal with small LR
:::
Then, if we increase our learning rate too much, we bounce around again.
::: {#fig-local-min-largeLR}
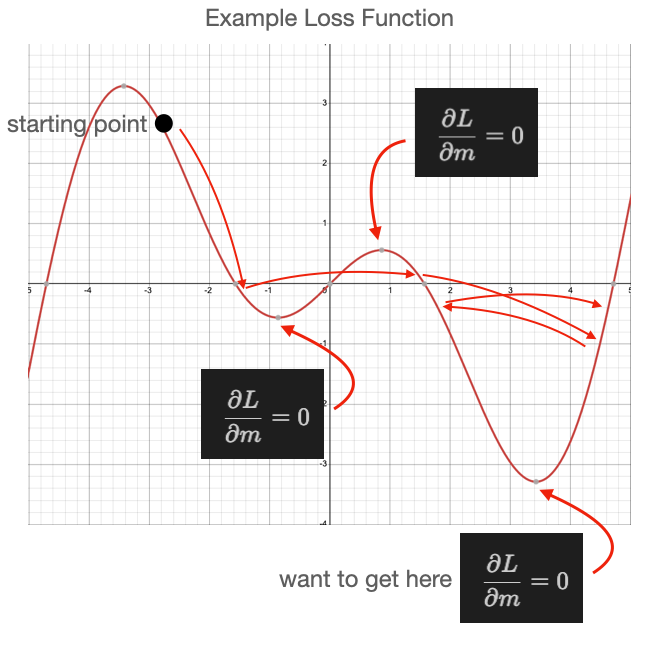
Local minimal with large LR
:::
What we want to do in this situation is start with a large learning rate and
slowly reduce its size as we progress.
That is shown in this next figure.
::: {#fig-local-min-variableLR}
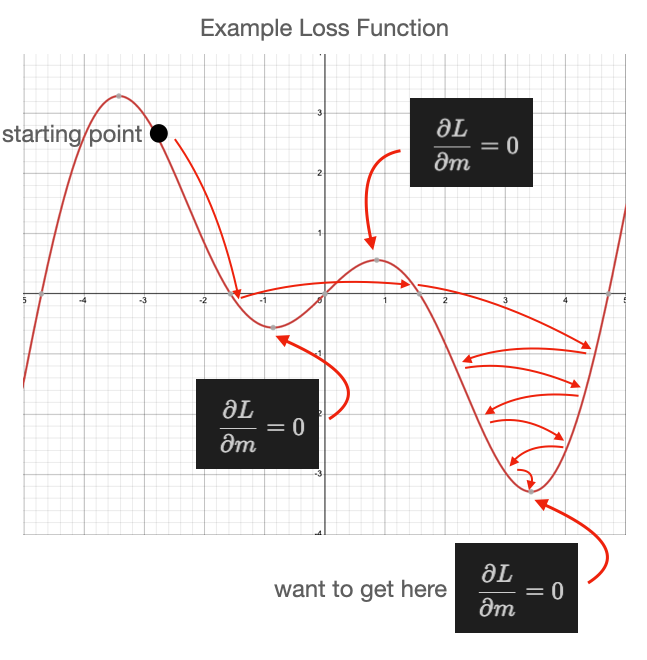
Local min with variable LR
:::
As you can see, this process is not perfect and could still land in a local
minimum, but it is important to be aware of these behaviors as you utilize SGD
in machine learning.
So let's continue, we'll build functions we can use to update our fit
parameters, $m$ and $b$.
```{python}
def updated_m(x,y,m,b,learning_rate):
dL_dm = - 2 * x * (y - model(x,m,b))
dL_dm = np.mean(dL_dm)
return m - learning_rate * dL_dm
def updated_b(x,y,m,b,learning_rate):
dL_db = - 2 * (y - model(x,m,b))
dL_db = np.mean(dL_db)
return b - learning_rate * dL_db
```
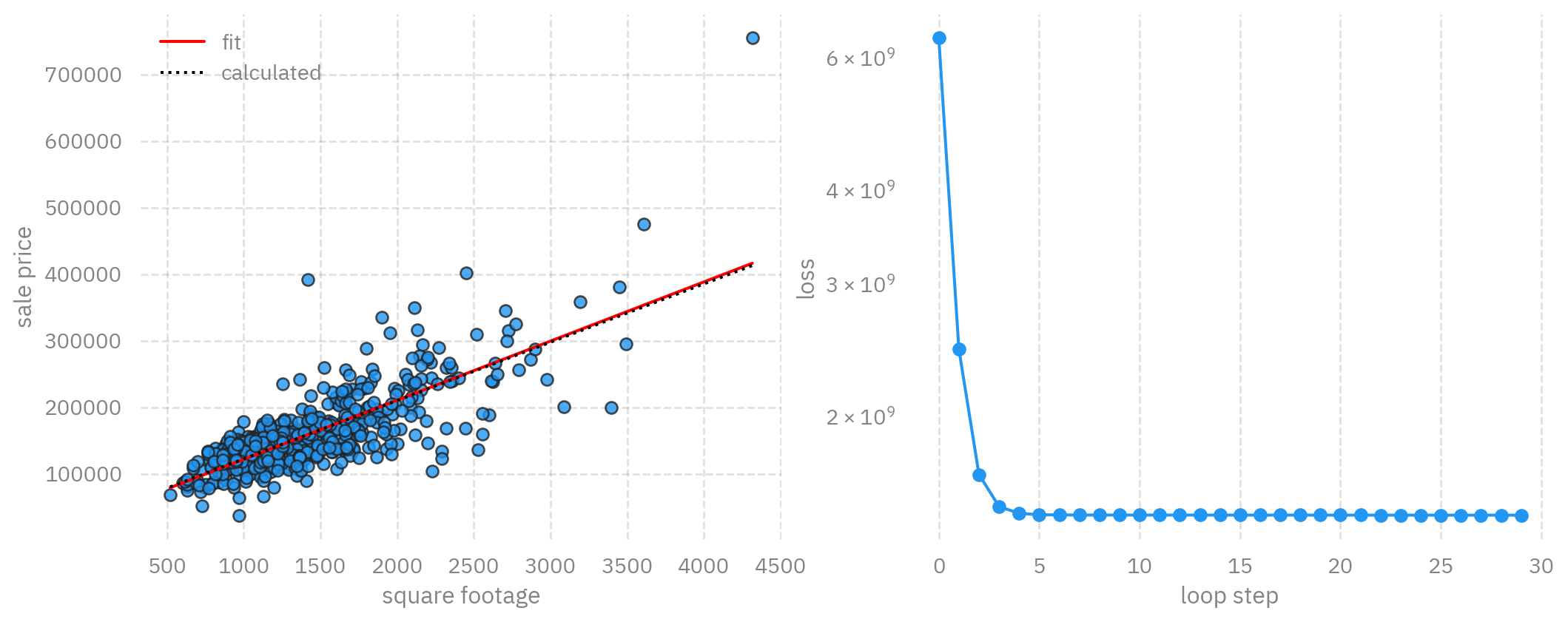
## Putting it together
We can now randomly select our initial slope and intercept:
```{python}
m = 5.
b = 1000.
print(f"y_i = {m:.2f} * x + {b:.2f}")
# print('y_i = %.2f * x + %.2f' % (m,b))
```
Then we can calculate our Loss function:
```{python}
l = loss(x,y,m,b)
print(f'first 10 loss values: {l[:10]}')
```
```{python}
learning_rate = 1e-9
m = updated_m(x,y,m,b,learning_rate)
b = updated_b(x,y,m,b,learning_rate)
print('y_i = %.2f * x + %.2f previously calculated: y_i = %.2f * x + %.2f' % (m,b,m_calc,b_calc))
plot_data(x,y,m,b)
```
```{python}
# set our initial slope and intercept
m = 5.
b = 1000.
# batch_size = 60
# set a learning rate for each parameter
learning_rate_m = 1e-7
learning_rate_b = 1e-1
# use these to plot our progress over time
loss_history = []
# convert panda data to numpy arrays, one for the "Ground Living Area" and one for "Sale Price"
data_x = data['GrLivArea'].to_numpy()
data_y = data['SalePrice'].to_numpy()
# we run our loop N times
loop_N = 30
for i in range(loop_N):
# update our slope and intercept based on the current values
m = updated_m(data_x,data_y,m,b,learning_rate_m)
b = updated_b(data_x,data_y,m,b,learning_rate_b)
# calculate the loss value
loss_value = np.mean(loss(data_x,data_y,m,b))
# keep a history of our loss values
loss_history.append(loss_value)
# print our progress
mstr = " ".join([
f"[{i:03d}]",
f"dy_i = {m:.2f} * x + {b:.2f}",
f"previously calculated: y_i = {m_calc:.2f} * x + {b_calc:.2f}",
f"loss: {loss_value:.2f}",
])
print(mstr)
# print(
# '[%03d] dy_i = %.2f * x + %.2f previously calculated: y_i = %.2f * x + %.2f loss: %f' % (i,m,b,m_calc,b_calc,loss_value))
# close/delete previous plots
plt.close('all')
dfigsize = plt.rcParams['figure.figsize']
# create a 1 by 2 plot grid
fig,ax = plt.subplots(1,2, figsize=(dfigsize[0]*2,dfigsize[1]))
# lot our usual output
plot_data(data_x,data_y,m,b,ax[0])
# here we also plot the calculated linear fit for comparison
line_x = np.arange(data_x.min(),data_x.max())
line_y = line_x * m_calc + b_calc
ax[0].plot(line_x,line_y, color="#000", linestyle=":" ,label='calculated')
# add a legend to the plot and x/y labels
ax[0].legend()
ax[0].set_xlabel('square footage')
ax[0].set_ylabel('sale price')
# plot the loss
loss_x = np.arange(0,len(loss_history))
loss_y = np.asarray(loss_history)
ax[1].plot(loss_x,loss_y, 'o-')
ax[1].set_yscale('log')
ax[1].set_xlabel('loop step')
ax[1].set_ylabel('loss')
plt.show()
# gives us time to see the plot
time.sleep(2.5)
# clears the plot when the next plot is ready to show.
ipydis.clear_output(wait=True)
```
## Homework
### Mini Batch Training
In AI, datasets are often very large and cannot be processed all at once as is
done in the loop above.
The data is instead randomly sampled in smaller
_batches_ where each _batch_ contains `batch_size` inputs.
How can you change the loop above to sample the dataset in smaller batches?
Hint: Our `data` variable is a Pandas `DataFrame` object, search for "how to
sample a DataFrame".
Instead of using the entire dataset like:
```python
data_x = data['GrLivArea'].to_numpy()
data_y = data['SalePrice'].to_numpy()
```
Use
```python
data_batch = data.sample(batch_size)
data_x = data_batch['GrLivArea'].to_numpy()
data_y = data_batch['SalePrice'].to_numpy()
```
You also have to adjust the loop_N accordingly to make sure that it loop over the entire datasets the same number of times.
```python
loop_N = 30*len(data)//batch_size
```
Please plot your learning curve for different batch size, such as 32, 64, 128, 256, 512.
### Learning rate issue (Bonus)
As described above, if the learning rate is too large, it will affect the convergence. Do your training with (batch_size = 64, learning_rate_m = 1e-7, learning_rate_b = 1e-1). Then linearly increase the batch size and learning rate until you see the training does not converge.
```
(64, 1e-7, 1e-1)*1
(64, 1e-7, 1e-1)*2
(64, 1e-7, 1e-1)*4
(64, 1e-7, 1e-1)*8
...
```
**How to submit your homework**
- Fork the github repo to your personal github
- Make change to the 01_linear_regression_sgd.ipynb, and then push to your personal github
- Provide the link of 01_linear_regression_sgd in the personal github.
<!--
Follow the below instruction on how to do this:
https://github.com/argonne-lcf/ai-science-training-series/blob/main/00_introToAlcf/03_githubHomework.md
-->
<details closed><summary><h2>Homework Answer</h2></summary>
Let us define a train function which allow us to try different hyperparameter setups.
```{python}
x = data['GrLivArea'].to_numpy()
y = data['SalePrice'].to_numpy()
def train(batch_size, epochs=30, learning_rate_m = 1e-7, learning_rate_b = 1e-1):
loss_history = []
num_batches = len(data)//batch_size
loop_N = epochs*num_batches
m = 5.
b = 1000.
for i in range(loop_N):
data_batch = data.sample(batch_size)
data_x = data_batch['GrLivArea'].to_numpy()
data_y = data_batch['SalePrice'].to_numpy()
# update our slope and intercept based on the current values
m = updated_m(data_x,data_y,m,b,learning_rate_m)
b = updated_b(data_x,data_y,m,b,learning_rate_b)
# calculate the loss value
loss_value = np.mean(loss(data_x,data_y,m,b))
# keep a history of our loss values
loss_history.append(loss_value)
#loss_last_epoch = np.sum(loss_history[-num_batches:]*batch_size)/len(data)
return m, b, np.mean(loss(x,y,m,b))
```
## Minibatch training
```{python}
print('previously calculated: y_i = %.2f * x + %.2f loss: %f\n=======================================' % (m_calc,b_calc,loss_value))
for bs in 64, 128, 256, 512:
m, b, l = train(bs, epochs=30)
print(f"batch size: {bs}, m={m:.4f}, b={b:.4f}, loss={l:.4f}")
```
We see that eventually, we all get similar results with the minibatch training. Of course, here, we still keep the same learning rate. A gene
## Learning rate
```{python}
for i in 1, 2, 4, 8:
bs, lrm, lrb = np.array([64, 1e-7, 1e-1])*i
bs = int(bs)
m, b, l = train(int(bs), epochs=30, learning_rate_m = lrm, learning_rate_b = lrb)
print(f"batch size: {bs}, m={m:.4f}, b={b:.4f}, loss={l:.4f}")
```
We can see that, if we increase the batch size and the learning rate
proportionally, at certain point, it does not converge for example for the case
batch size = 512. To increase the learning rate proportional to the batch size
is a general practice. However, if the learning rate is too large, it will
continue to move around without finding a local minimum. One trick, people can
do is to start with a smaller learning rate in the first few steps / epochs,
and once the optimization becomes stable, increase the learning rate
proportional to the batch size.
</details>