LLMs on Polaris
2023-10-13
October 10 – 12, 2023 \hspace{5pt} ![]()
ALCF Hands-on
HPC Workshop
Status of Large Language Models1

Emergent Abilities

Emergent abilities of Large Language Models Yao et al. (2023)
Training LLMs


Recent Work (2017 – Now)
Recent Work
Life-Cycle of the LLM
Data collection + preprocessing
Pre-training
- Architecture decisions:
{model_size, hyperparameters,
parallelism, lr_schedule, ...}
- Architecture decisions:
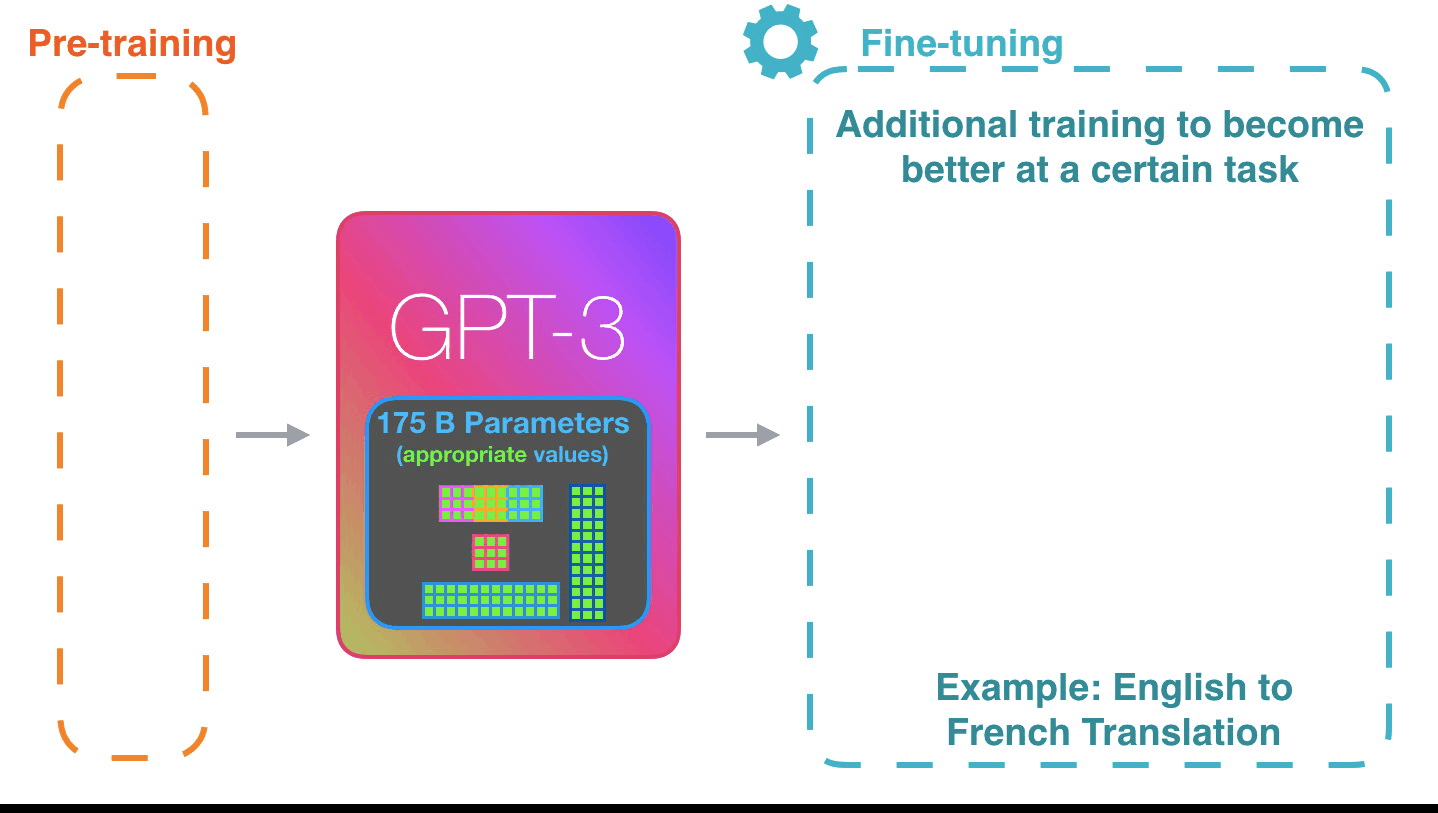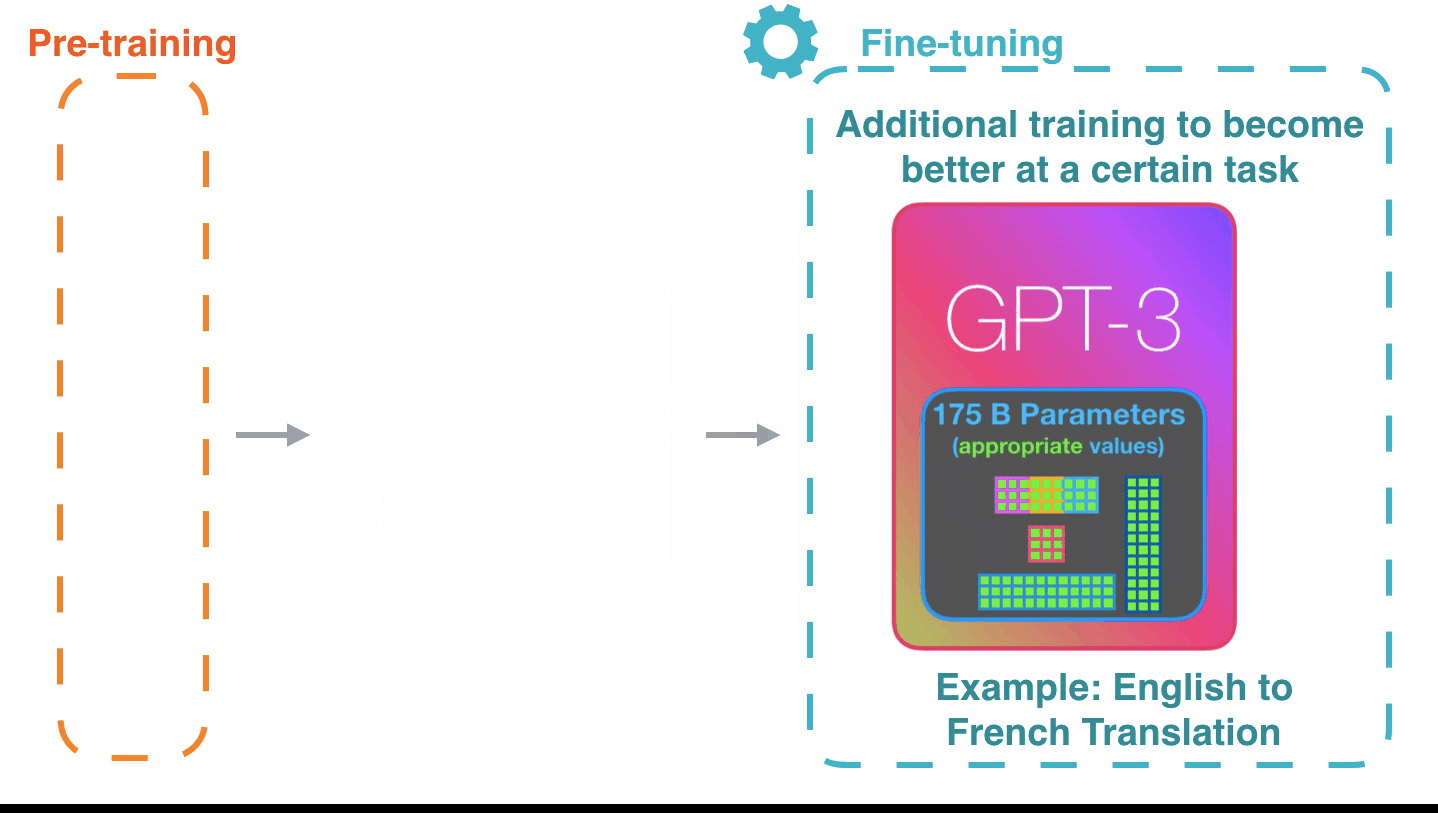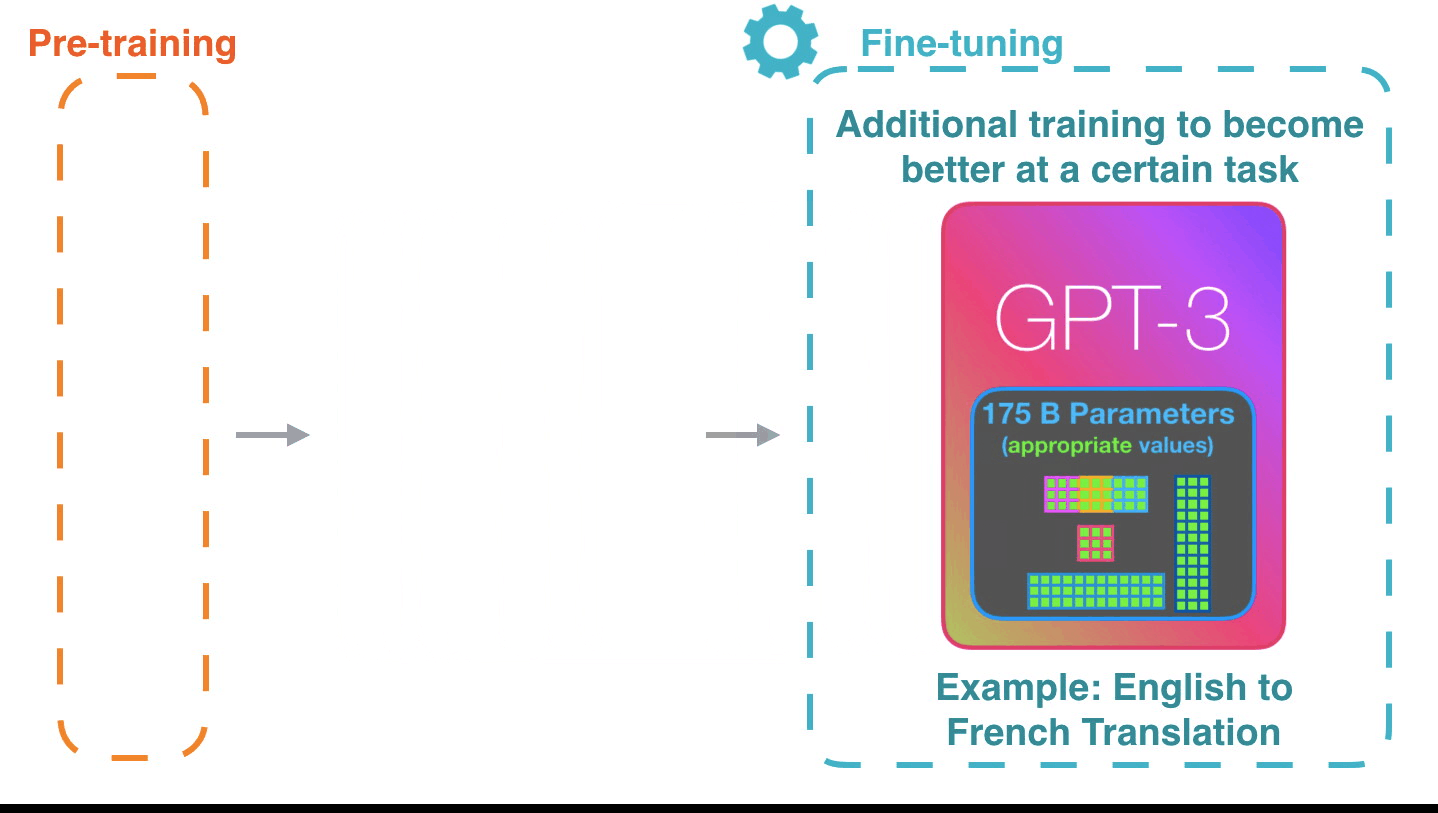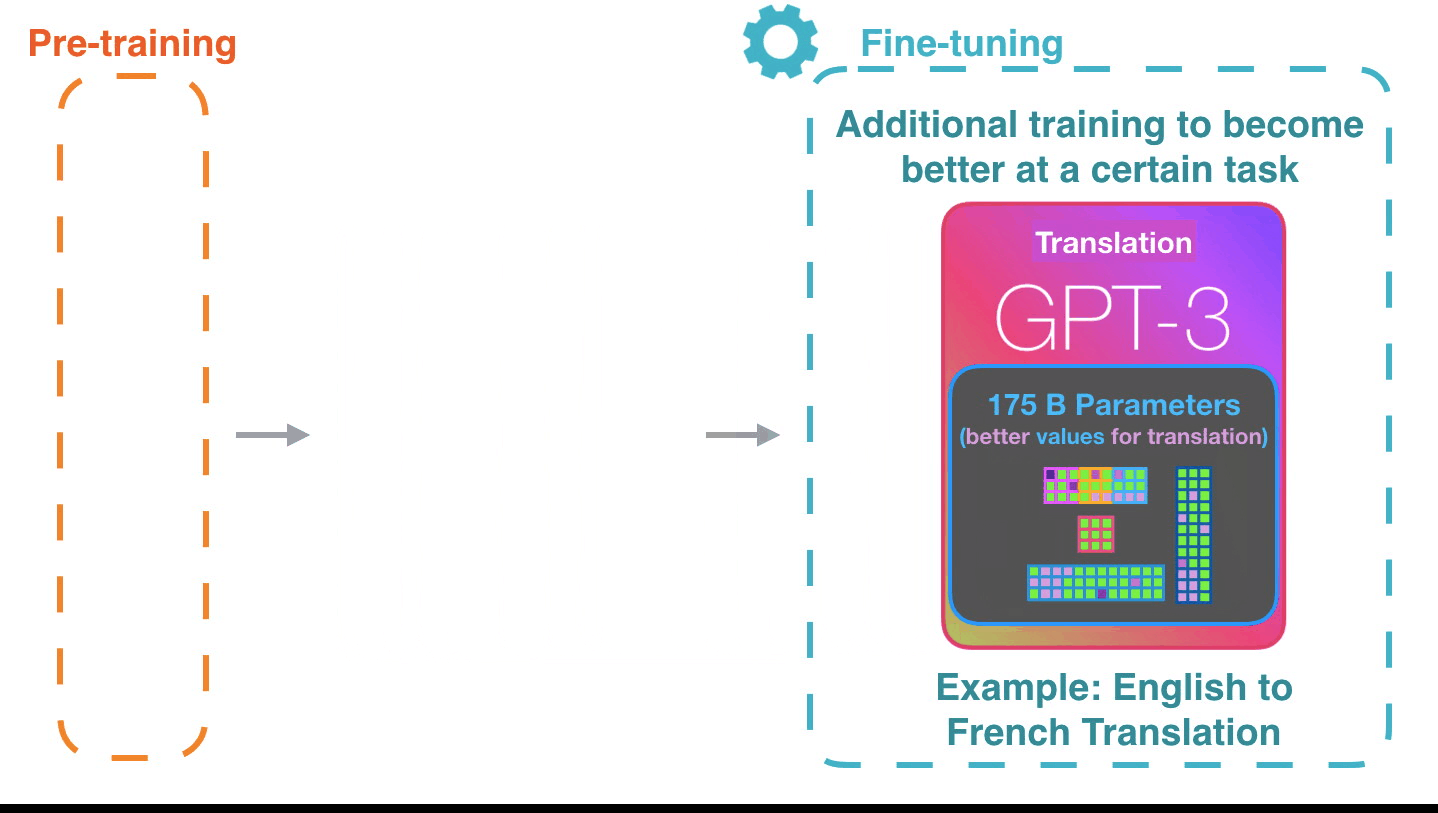
Supervised Fine-Tuning
- Instruction Tuning
- Alignment
Deploy (+ monitor, re-evaluate, etc.)
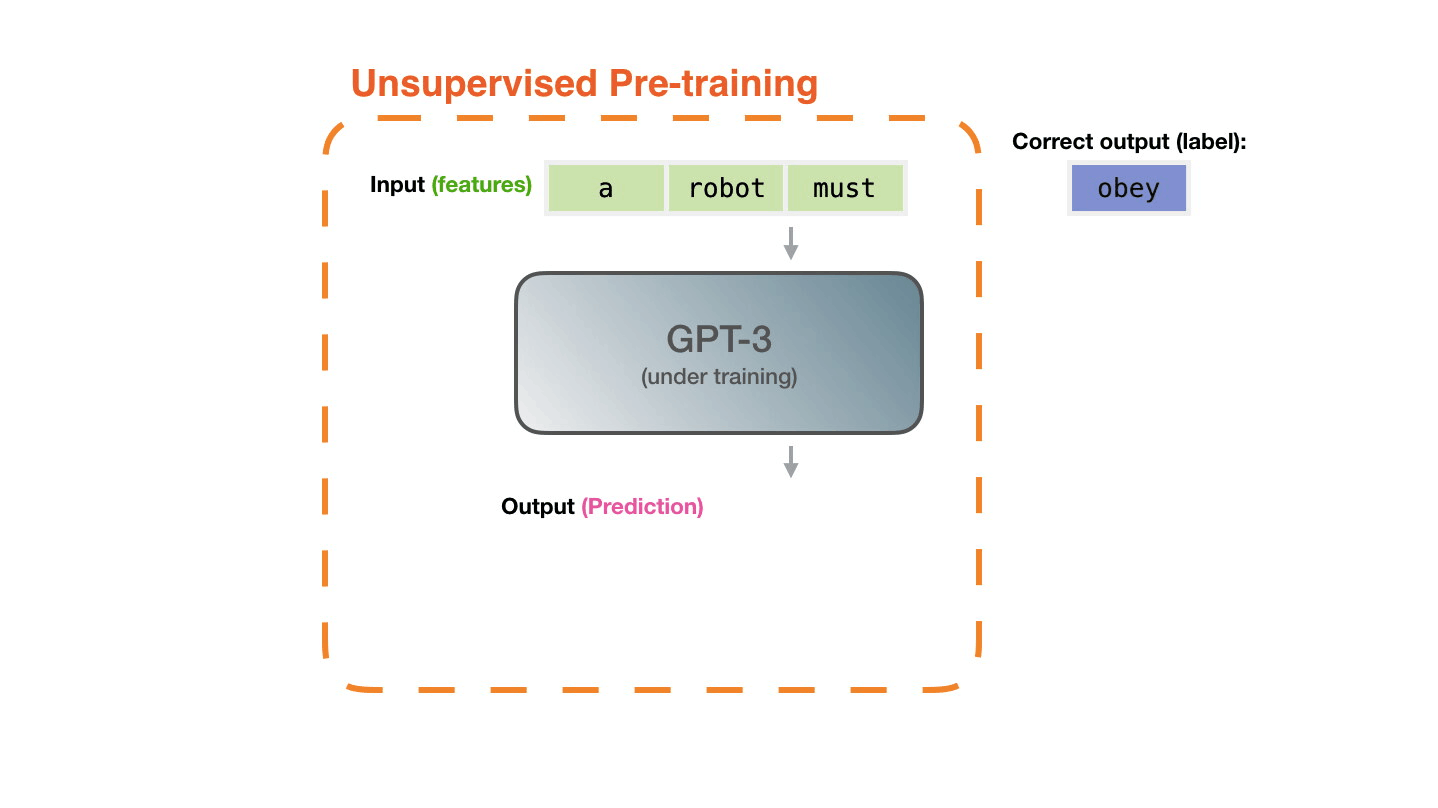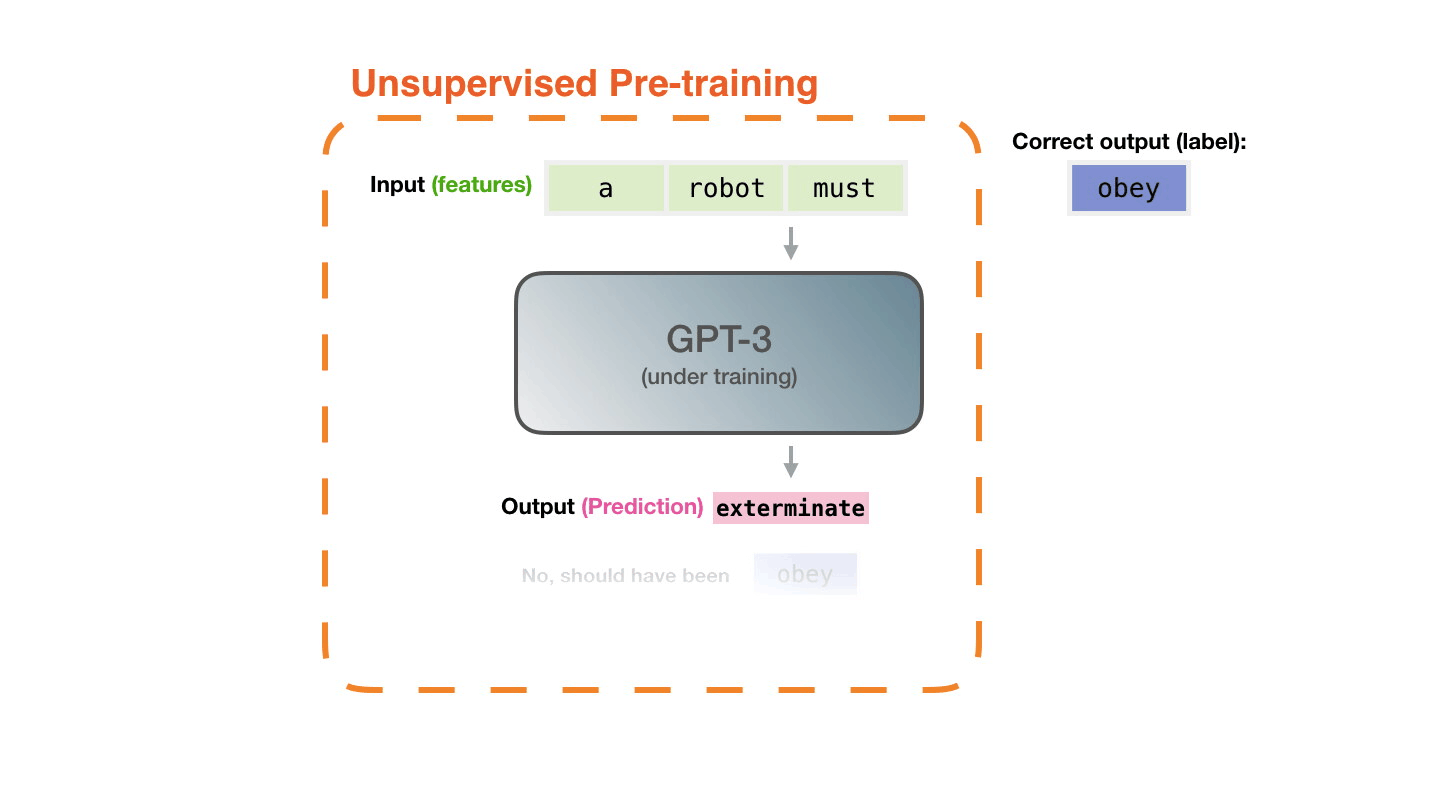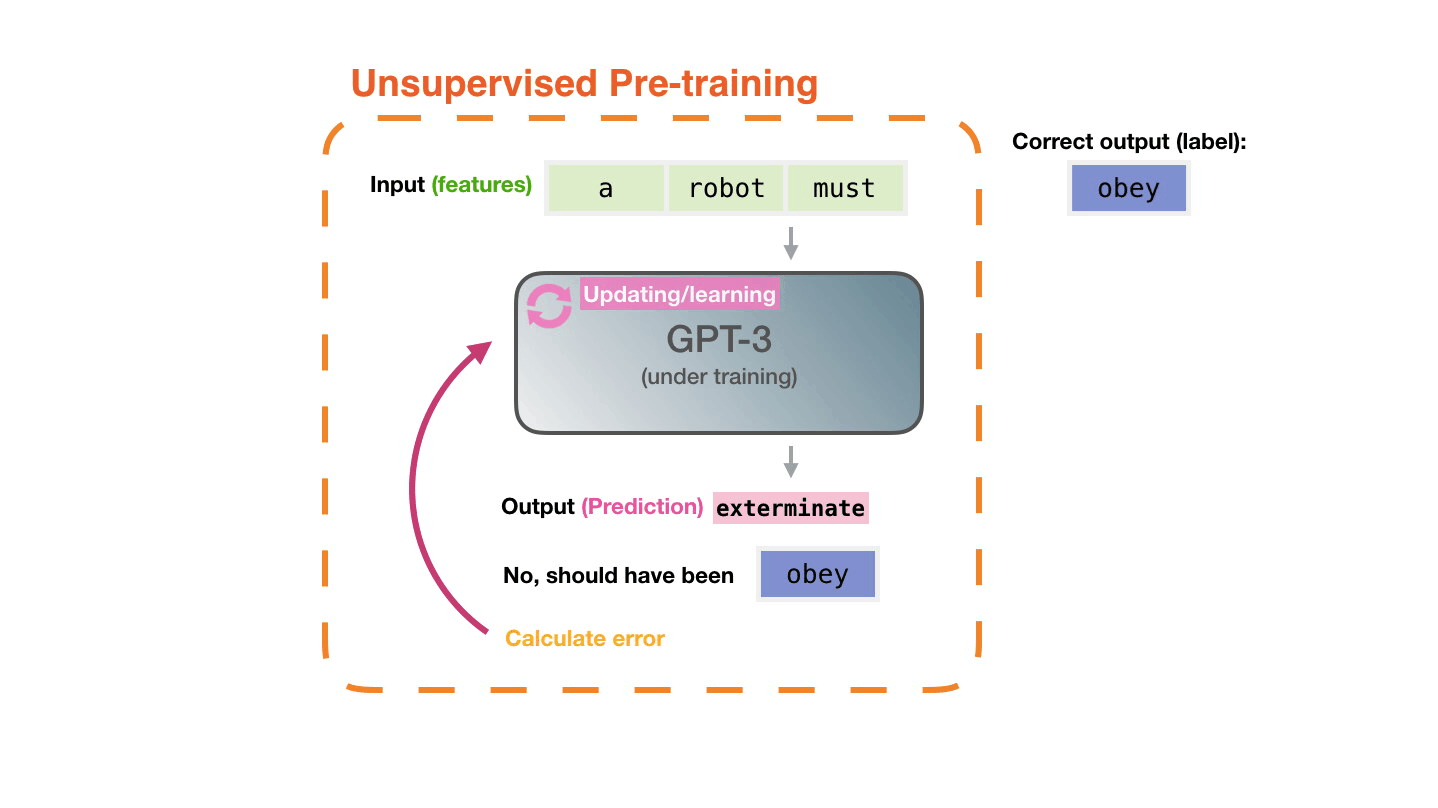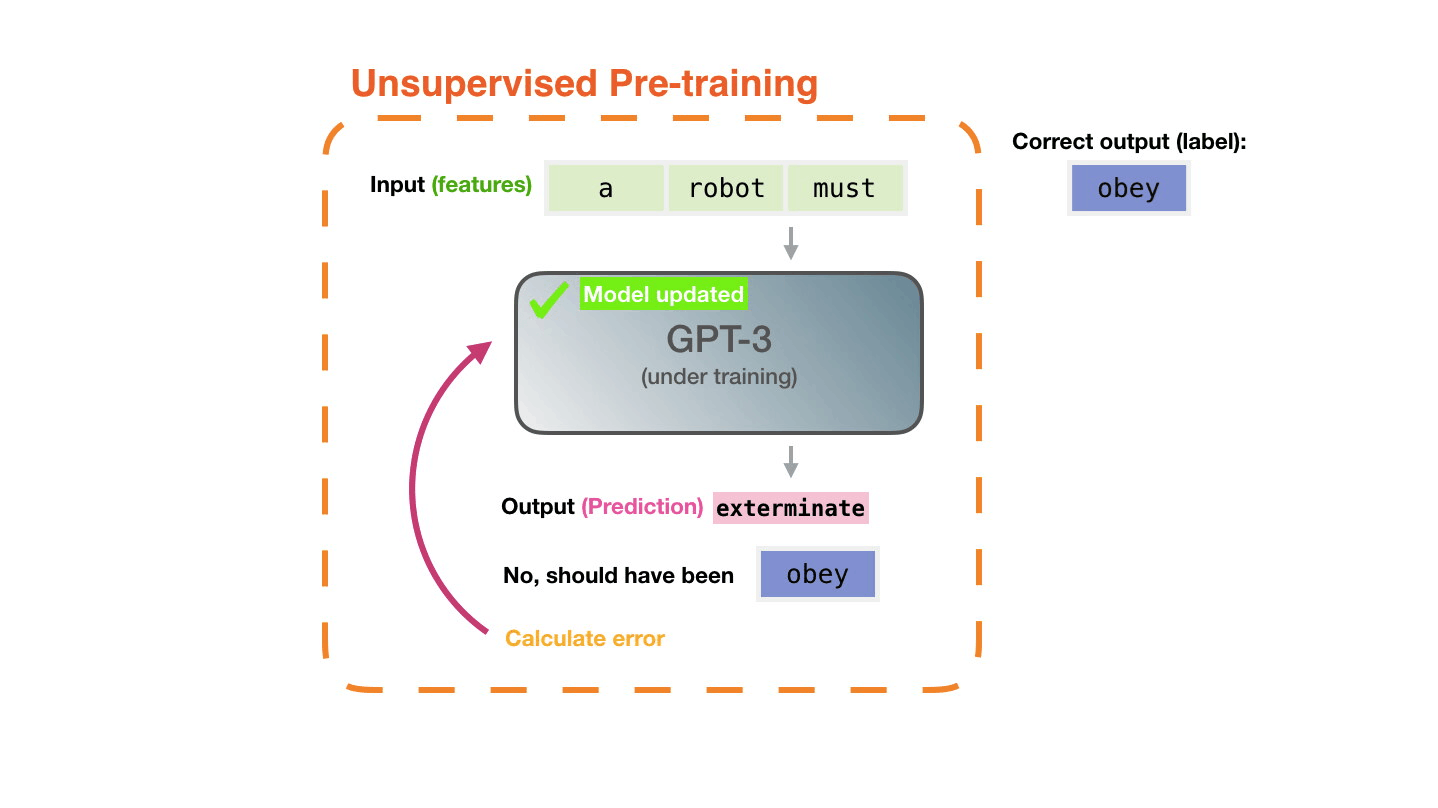
Life-Cycle of the LLM: Pre-training
Figure 4: Pre-training: Virtually all of the compute used during pretraining phase
Life-Cycle of the LLM: Fine-Tuning
Transformer Architecture
Vaswani et al. (2017)
Data Parallelism
- Data Parallelism:
- The simplest and most common parallelism technique. Workers maintain identical copies of the complete model and work on a subset of the data.
DDPsupported in PyTorch native.
- ZeRO Data Parallel
- ZeRO powered data parallelism is shown below1

Tensor Parallelism

3D Parallelism
DP+TP+PP(3D) Parallelism

3D Parallelism illustration. Figure from: https://www.deepspeed.ai/
3D Parallelism
DP+TP+PP(3D) Parallelism

Figure taken from 3D parallelism: Scaling to trillion-parameter models
DeepSpeed4Science

Latent space of biologically meaningful properties for SARS-CoV-2 genomes
Loooooooooong Sequence Lengths

| Sequence Length | Old Megatron-DeepSpeed (TFLOPS) | New Megatron-DeepSpeed (TFLOPS) |
|---|---|---|
| 2k | 25 | 68 |
| 4k | 28 | 80 |
| 8k | OOM | 86 |
| 16k | OOM | 92 |
| 32k | OOM | 100 |
| 64k | OOM | 106 |
| 128k | OOM | 119 |
| 256k | OOM | 94 |
Loooooooooong Sequence Lengths
- Working with Microsoft DeepSpeed team to enable longer sequence lengths (context windows) for LLMs1


SEQ_LEN for both 25B and 33B models [WIP]Links
- Hannibal046/Awesome-LLM
![Awesome]()
- Mooler0410/LLMsPracticalGuide
- Large Language Models (in 2023)
- The Illustrated Transformer
- Generative AI Exists because of the Transformer
- GPT in 60 Lines of Numpy
- Better Language Models and their Implications
- Progress / Artefacts / Outcomes from 🌸 Bloom BigScience
Acknowledgements
This research used resources of the Argonne Leadership Computing Facility,
which is a DOE Office of Science User Facility supported under Contract DE-AC02-06CH11357.
References
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. “Attention Is All You Need.” https://arxiv.org/abs/1706.03762.
Yang, Jingfeng, Hongye Jin, Ruixiang Tang, Xiaotian Han, Qizhang Feng, Haoming Jiang, Bing Yin, and Xia Hu. 2023. “Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond.” https://arxiv.org/abs/2304.13712.
Yao, Shunyu, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. “Tree of Thoughts: Deliberate Problem Solving with Large Language Models.” https://arxiv.org/abs/2305.10601.
